새소식
반응형
데이터를 적재하면서 가장 중요한 것은 무엇일까요?
여러가지 이유가 있겠지만 무엇보다 그 데이터가 정상적으로 잘 적재되었는지 여부 입니다.
많은 사람들이 적재를 어떻게 하면 "빠르고 효율적으로 적재 할 수 있나?" 에 초점을 많이 둡니다.
하지만 이 데이터가 정상적으로 A 👉🏻 B 들어왔는지는 많이 고민하지 않는 것 같습니다.

이 글에서는 실제로 구현한 코드를 보여주진 않습니다. (회사에서는 제가 구현을 했지만..)
컨셉을 주로 설명하며, 각자가 맞게 회사 시스템에 녹일 수 있으면 좋겠습니다.
데이터를 가공하여 계산 된 데이터를 적재하는 경우는 그 데이터가 정확하게 나온 지 여부를 확인하지만 원천 데이터에서 데이터를 가져올 경우 데이터를 맞게 가져왔는지 확인이 중요하다고 봅니다.
예를 들어 데이터를 더욱 많이 가져왔거나 중복으로 2번 가져왔거나 하는 경우 데이터를 분석 함에 있어서 매우 치명적이라고 생각 됩니다. 약간의 오차로 인해서 의사 결정에 매우 치명적일 수 있습니다.
그래서 데이터가 정상적으로 적재가 되었는지 원천 데이터와 최종 목적지의 데이터를 비교해서 데이터의 적재가 정상적으로 이루어졌는지 확인은 매우 중요하다고 봅니다. 저는 2가지 방법을 통해서 데이터가 정상적으로 잘 적재되었는지 체크하였습니다.
첫번째, 원천 데이터와 목적지 데이터의 건수가 같은지 비교
두번째, 목적지 데이터의 유니크 키값을 이용하여, 중복이 없는지 비교
이 글에서 설명하는 내용은 우선 RDBMS(이하 RDB)에서 데이터를 이관 하였을 때 기준으로 작성 하였습니다. RDB에서도 무조건 이 글의 내용을 적용할 순 없고, 몇가지 조건이 필요합니다. 또한 이관 하는 목적지는 Big Query 기준으로 작성 하였습니다. 개인적인 생각으로 원천 데이터가 RDB이면 이 내용을 적용하기에 무리가 없다고 보입니다.
1. 비교하고자 하는 원천 테이블에 로그의 적재 시간이 있어야 합니다.
2. 비교하고자 하는 원천 테이블에 고유한 키 값이 있어야 합니다.
3. 모니터링용 RDB가 필요합니다. (데이터 저장 및 메타정보 저장)
이렇게 최소한의 조건이 필요한 이유는 데이터를 검증 하기 위해서 너무 많은 비용 또는 시스템에 부하를 줄 경우 사용하기 어렵다는 점 때문입니다. 데이터의 정합성을 체크하는데 시스템에 부하를 줘서 시스템이 갑자기 장애가 난다면 매우 큰 일이라고 봅니다.

간단하게(?) 구성도를 보면 다음과 같이 만들 수 있습니다.

위에서 언급을 조금 했는데 모니터링 RDB에는 메타 정보 테이블이 필요합니다.
그 이유는 위에서 언급한 1,2번의 컬럼 내용을 저장하기 위함입니다. 아주 정확하게 데이터 용어 사전을 모두 맞춰서 개발을 하는 회사라면 이러한 부분이 크게 필요 없겠지만 그렇지 않은 경우 매우 필요 합니다. 데이터를 적재하는 날짜 조건 컬럼의 이름이 다를 수 있고 내가 지정한 고유한 키값이 서로 다를 수도 있습니다.
또는 가끔 이 테이블은 고유한 값이 없이 건수만 체크 해야 할 경우도 있습니다. 아니면 날짜가 없는 UPDATE가 일어나는 메타정보 테이블인데, 빈번하게 업데이트가 일어나므로 중복만 체크해야 하거나 하는 경우도 있습니다. (BigQuery의 경우 PK가 없기 때문에 고유하게 저장한지 여부를 정책으로 걸어두기 어렵다.)
데이터가 RDB 에서 Data Lake 또는 Data Warehouse로 잘 넘어왔는지 볼 때 가장 단순하면서 확실한 방법이라고 생각 됩니다. 데이터가 2021.06.01 ~ 2021.06.02까지 몇건인지 RDB에서 건수를 체크하고 우리가 사용하는 저장소(저는 BigQuery를 사용)의 건수와 동일한지 비교 할 수 있습니다.
그리고 여기서 1번 조건인 로그의 적재 시간이 필요합니다. 정확히는 RDB에 데이터가 입력 된 시간이라고 볼 수 있겠네요. 많은 사람들이 보통 CREATE_DATE 등의 컬럼을 통해서 NOW() 또는 Default를 통해서 현재 시간을 컬럼에 넣어서 INSERT 합니다. 이로 인해서 이 로그가 언제 RDB에 입력되었는지 알 수 있습니다.
건수 체크를 효율적으로 하기 위해서 위에서 언급한 CREATE_DATE에 INDEX를 만들어서 부하를 줄이고 효율적으로 체크가 가능합니다. 보통 다음과 같이 Query문을 통해서 건수 체크를 할 수 있습니다.
|
SELECT COUNT(*)
FROM TABLE
WHERE CREATE_DATE >= '2021-06-01' AND CREATE_DATE < '2021-06-02'
|
cs |
이렇게 날짜 조건을 통해서 정확하게 건수를 가져올 수 있습니다. 이렇게 건수를 모니터링 RDB에 저장하고 이를 비교함으로써 건수를 체크 할 수 있습니다. 날짜를 통해서 정확히 가져왔기 때문에 데이터의 건수를 체크 했을때 다를 경우 중복이나 덜 가져왔다고 볼 수 있습니다.
그런데 여기서 한가지 의문이 듭니다. 🙋♂️ 그럼 전체적인 건수를 세면 더욱 정확하지 않을까? 라는 생각이 듭니다.
하지만 이 부분은 불가능 합니다. 왜 일까요?
RDB (Source)는 OLTP이기 때문에 데이터는 빈번하게 계속해서 들어옵니다. 하지만 우리가 쓰는 저장소의 경우 OLAP의 환경이기 때문에 우리가 ETL을 해주지 않으면 데이터는 그대로 입니다. 그렇게 때문에 날짜 조건으로 정확하게 끊지 않을 경우 (어디부터 어디까지라고 명시하지 않을 경우) RDB의 데이터는 계속해서 변하기 때문에 정확히 끊어서 체크 해야 합니다.

이렇게 데이터를 계속해서 시간 또는 날짜 단위로 비교하여 여러가지 지표 또한 만들 수 있습니다.
모니터링 RBD에 쌓는 가장 큰 이유는 데이터의 건수 체크를 할수도 있지만 데이터의 건수 수세를 볼 수도 있습니다.
언제 얼마나 쌓였고, 데이터의 증감률과 같은 History 데이터도 함께 볼 수 있기 때문에 여러모로 좋습니다.
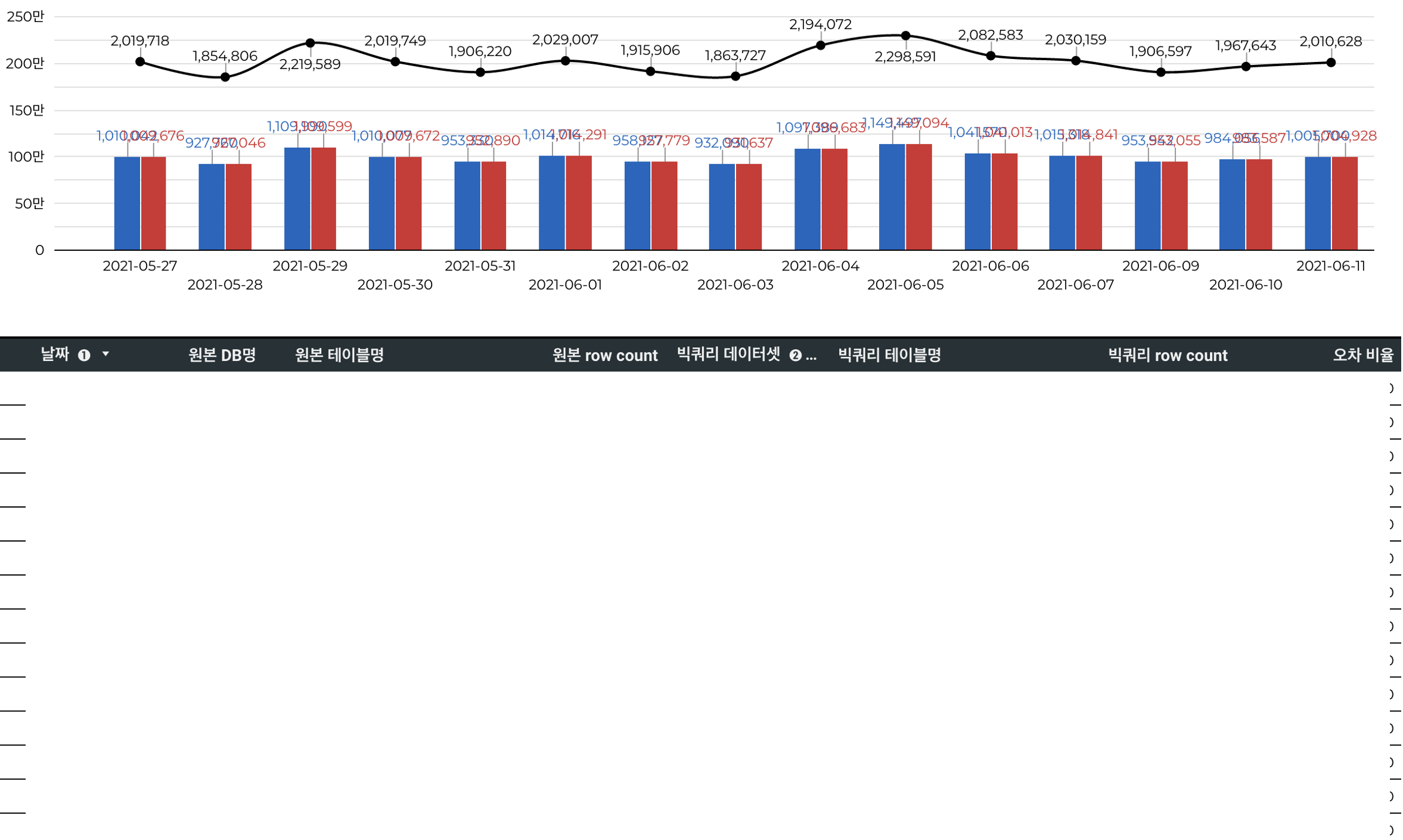
데이터의 건수가 잘 맞는다고 하여도, 중복을 알수는 없습니다. 특히 실제 RDB에서 중복이 발생 할 경우 더욱이 그렇습니다. 그럴 경우 우리쪽의 데이터를 분석하는 분석쪽에도 문제지만 RDB의 데이터를 직접적으로 보는 고객들의 입장에서도 아주 큰 문제 입니다.
그렇게 때문에 중복을 체크 함으로써 우리가 사용하는 Data warehouse의 중복뿐 아니라 RDB의 데이터를 추가적으로 검증하는 효과를 볼 수 있습니다. (실제로 몇건 잡았습니다.)
여기서도 모니터링 RDB의 메타 테이블이 필요합니다. 위에서 언급한 로그의 적재시간과 똑같이 유니크한 컬럼의 경우도 이름이 모두 다를 수 있기 때문입니다. (아니면 없거나.. 없으면 중복 체크를 하지 않게 만들어야 합니다.)
|
SELECT id,COUNT(*) AS cnt
FROM TABLE
GROUP BY id
HAVING count(*) > 1
|
cs |
위와 같이 유니크 컬럼을 통해서 중복을 체크하고 건수가 1개 이상일 경우 모니터링 RDB에 저장하고 이를 Slack 같은 메신져를 통해서 알림을 줄 수 있습니다. 위의 작업의 경우 RDB의 데이터 보다는 주로 사용하는 Data warehouse(BigQuery)에서만 Query하여 가져왔습니다.
여기서 또한가지 의문이 들 수 있습니다. 저렇게 전체 테이블을 SELECT해서 건수를 가져오면 너무 비용이 많이 들지 않을까? 🤔 하지만 실제로는 그렇지 않습니다.
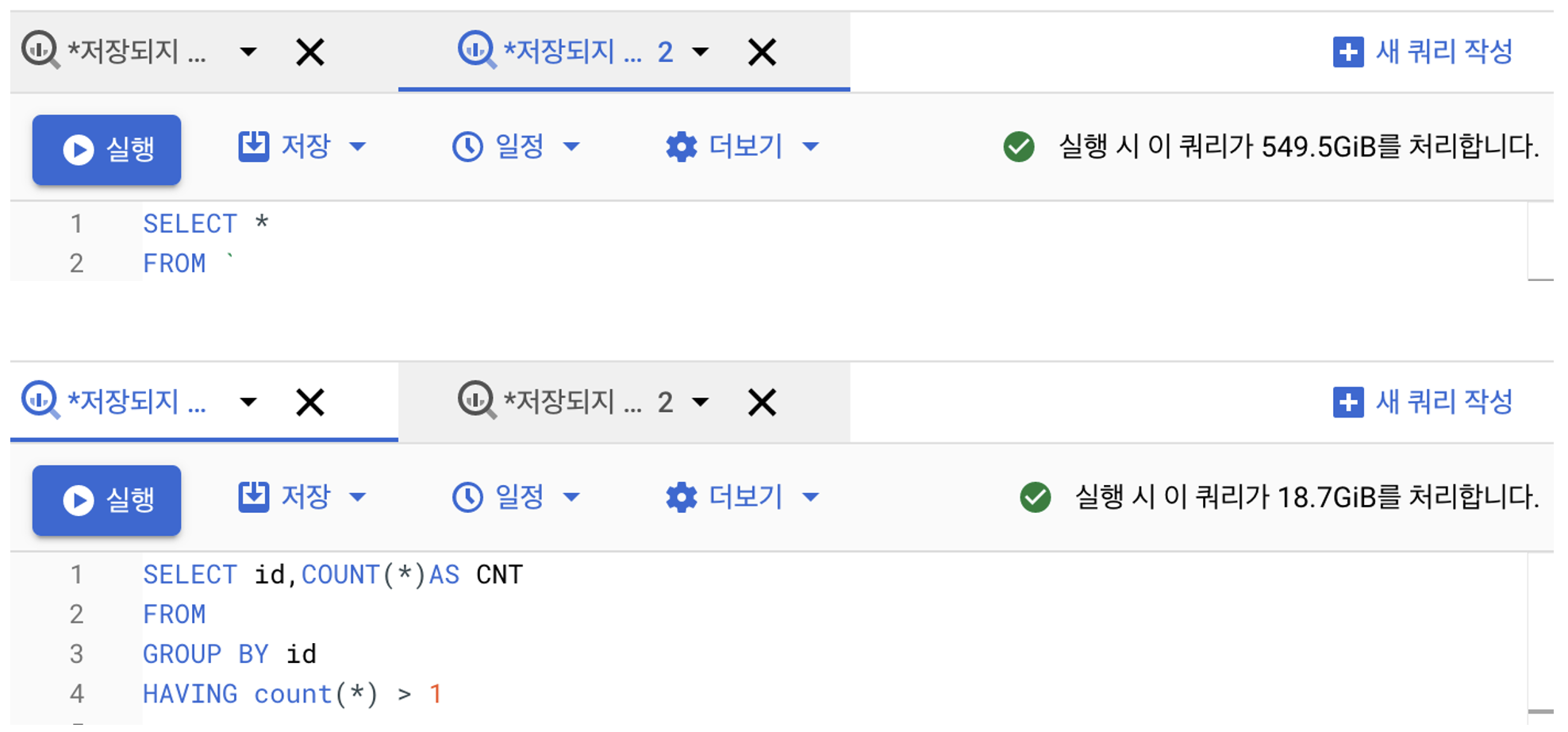
위에서 내용에서 보시면 엄청나게 큰 비용이 발생하지 않습니다.
중복 체크의 경우 하루에 1번 이루어지므로, 큰 비용은 아니라고 생각이 듭니다. (이 비용보다 이로인해 발생하는 문제가..더...)
추가적으로 위의서 발생한 데이터를 모니터링 RDB에 저장하고 이를 아래와 같이 Slack 알람으로 발송하여 중복을 확인 할 수 있습니다.
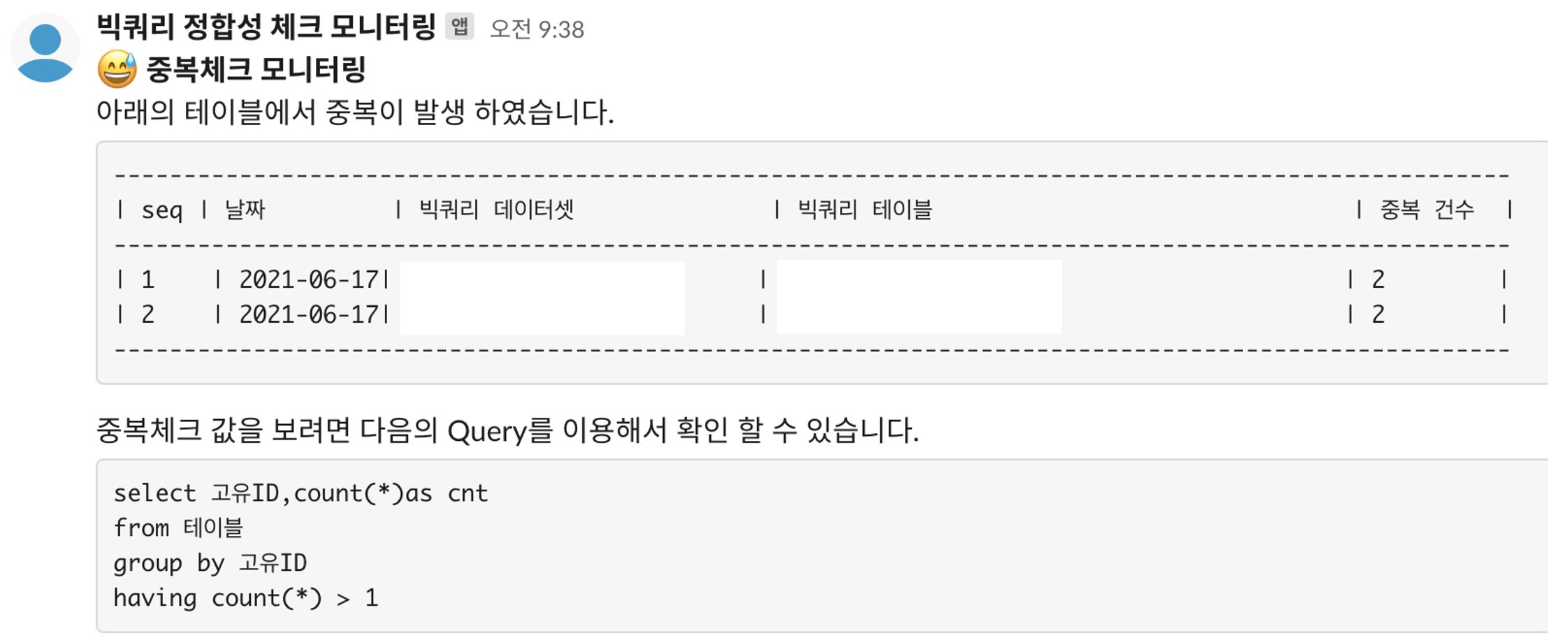
위의 메시지를 통해서 중복으로 데이터가 적재되었다는 것을 바로 확인 가능하고 이를 통해서 적절한 조치를 취할 수 있습니다.
생각보다 거창하거나 엄청난 시스템은 아니라고 생각합니다. 하지만 위의 2가지만 가지고도 엄청난 장애를 막을 수 있다고 봅니다. 저는 데이터는 정확해야 한다고 생각합니다. 데이터가 정확해야지 분석가 또는 사업이나 의사결정자에게 정확한 수치의 데이터를 제공하고 이를 기반으로 정확한 내용을 가지고 무언가를 할 수 있다고 봅니다. 데이터가 부정확 할 경우 그만큼 데이터를 관리하고 이관하는 데이터엔지니어가의 신뢰가 떨어진다고 봅니다.

데이터 빠르게 효율적으로 이관하는 것도 물론 매우 중요하지만 그만큼 데이터가 정확하게 들어갔는지 체크 하는 부분도 중요하다고 생각됩니다. 많은 분들이 위의 내용을 통해서 정확한 데이터를 볼 수 있기를 바랍니다. 🙏
글을 읽어 주셔서 감사합니다. 😀😀😀😀😀
| [ETL] RDB에서 데이터 ETL을 위한 최소한의 테이블 설계 (0) | 2023.02.02 |
|---|---|
| [공통] 데이터를 적재하고 보기까지 (2) | 2022.06.16 |
| 데이터 파이프라인 제작기 - 반정형 데이터편 (JSON) (2) | 2021.10.26 |
| 데이터 파인프라인 제작기 (0) | 2021.03.16 |
소중한 공감 감사합니다