



안녕하세요. 오랜만에 글을 쓰는 것 같습니다. 연말이라서 대외적으로 여러 가지 약속도 많고 일이 있어서 글을 못 쓴 것 같습니다. 써야 할 글은 많은데, 그러지 못한 거 같습니다. 다시 열심히 써야 할 것 같습니다.
오늘 소개 할 내용은 BigQuery의 클러스터링입니다. 이걸 처음 알았을 때 정말로 신선하고 너무 좋은 기능이라고 생각해서 나름대로 공부를 해서 이렇게 글을 올립니다. 클러스터링은 제가 공부하면서 개인적으로 생각하기에 RDB의 인덱스와 비슷한 것 같습니다. 어디까지나 개인적인 생각이지만 데이터를 정렬해서 가져오는 방법이나 클러스터링의 순서에 따라서 사용 여부가 결정되는 것을 보면 인덱스의 성질과 정말 비슷해 보입니다.
RDB에서도 복합 인덱스를 생성할때 순서에 따라서 인덱스를 Seek 할지 아니면 그대로 Scan 할지 판단합니다. 자세한 내용은 예전의 제 블로그가 글을 참고하시면 도움이 될 듯합니다. ( 복합 인덱스가 컬럼 순서에 따른 성능 ) 인덱스의 특성을 알면 BigQuery의 클러스터링을 사용하는데 정말 많이 도움 될 듯합니다. 하지만 모르셔도 어느 정도 문서를 읽어보고 특성을 파악하면 쓰는데 무리가 없을 듯합니다. 그래서 오늘은 제가 테스트해본 내용을 정리하여 글을 써봤습니다. 저의 개인적인 생각으로 어떻게 데이터를 가져오는지 같이 적어 봤습니다.
1. BigQuery 클러스터링이 뭐야?
클러스터링은 partition과는 다릅니다. 동시에 같이 생성이 가능하고 함께 쓰면 효과는 더욱 좋습니다. partition은 데이터를 어디 구역에 저장할지를 정하는 부분이라면 클러스터링은 그 구역에서 순서에 맞게 정렬을 시켜 둔 것이라고 볼 수 있습니다.
이와 유사하게, 클러스터링 열의 값을 기준으로 데이터를 집계하는 쿼리를
제출하면 정렬된 블록이 유사한 값으로 행을 배치하기 때문에 성능이 개선됩니다.
위와 같이 공식 홈페이지에는 정렬이라고 이야기하고 있습니다. 조금 더 이해를 돕기 위해서 그림을 통해서 한번 보겠습니다. 아래의 그림을 보면 구역을 나누는 것은 파티션이고 이 구역에서 데이터를 정렬 하는것은 클러스터링이라고 볼 수 있습니다.

기존에 파티션만 적용 할 경우 데이터가 정렬이 안되어 있기 때문에 가져올 때 파티션만 쓴다면 아마도 다음과 같이 데이터를 가져올 것 같습니다. BigQuery의 내부적인 데이터 Read를 알지 못하기에... 이것도 추측 입니다. 혹시 내부적으로 어떻게 동작하는지 논문이나 자료가 있으면 공유를 부탁드립니다.

아마도 위와 같이 정렬이 보장이 안돼기 때문에 파티션으로 나눠진 구역으로 가서 모든 데이터를 가져오려고 할 것입니다. 정렬이 보장이 안될 경우 어디서부터 어디까지 읽어야지 사용자가 원하는 데이터를 가져올 수 있을지 알 수 없기 때문입니다. 그렇다면 클러스터링이 있는 테이블에서 데이터를 읽으려고 하면 어떻게 읽을지도 예상해 보겠습니다.
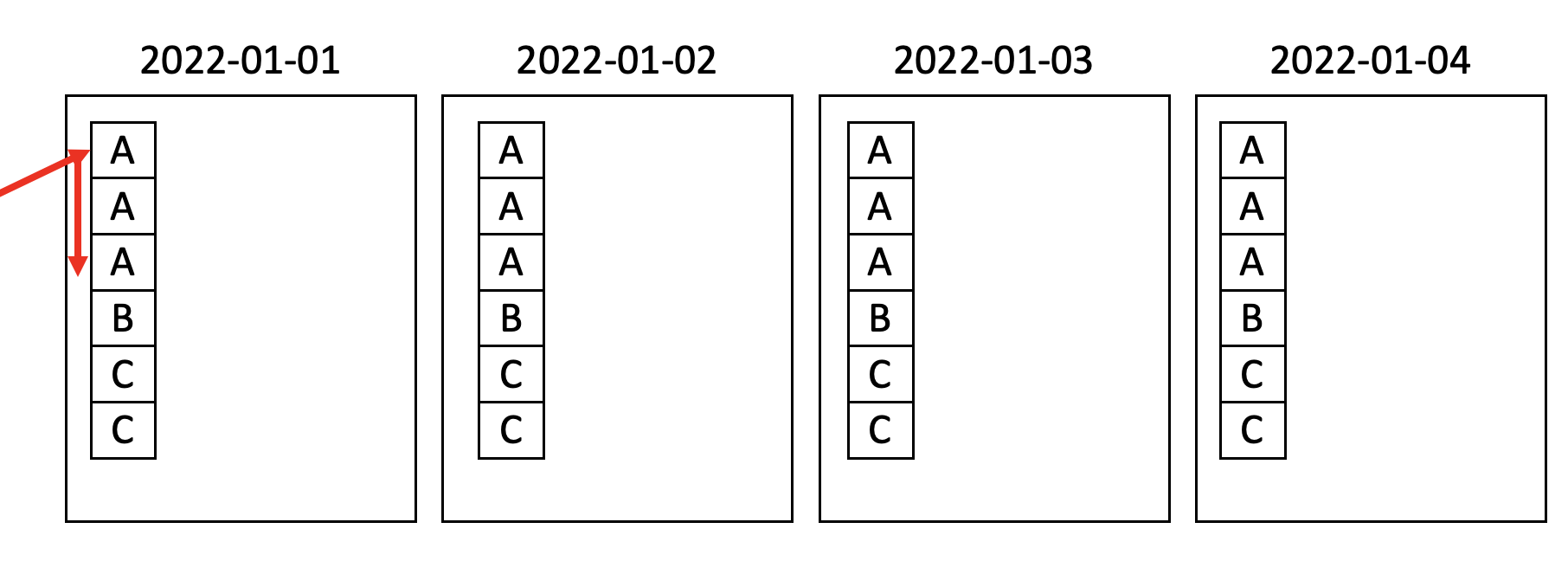
DB를 다루시고 인덱스를 공부하시는 분들이라면 아마도 쉽게 이해를 하실 겁니다. 인덱스 범위 검색입니다. 정렬이 보장되어 있기 때문에 끝까지 읽을 필요도 없고 데이터를 전부 읽을 이유도 없습니다. 이렇게 읽어가기 때문에 파티션으로 데이터를 읽을 때보다 훨씬 더 많이 비용과 성능에 이점을 가져갈 수 있습니다. 결론적으로 클러스터링은 데이터를 정렬하는 기법이고 이를 통해서 데이터의 처리 비용과 읽는 비용을 줄여서 성능과 비용에 이점을 볼 수 있다고 이해하면 좋을 듯합니다.
조금 더 자세한 내용은 아래의 공식 홈페이지에 있습니다.
https://cloud.google.com/bigquery/docs/clustered-tables
클러스터링된 테이블 소개 | BigQuery | Google Cloud
의견 보내기 클러스터링된 테이블 소개 이 문서에서는 BigQuery의 테이블 클러스터링 기능을 간략하게 설명합니다. 개요 BigQuery에서 클러스터링된 테이블을 만들 때, 테이블 데이터는 테이블 스키
cloud.google.com
2. 클러스터링을 만들어서 써보기
클러스터링을 만들어서 써보는 테스트를 해보겠습니다. 실제로 비용과 성능에 이점이 있는지 보기 위해서 파티션과 클러스터링을 함께 사용하는 테스트를 진행하도록 하겠습니다. 데이터의 경우 파이어 베이스 데이터를 사용하여 만들었습니다. 파티션은 event_timestamp로 잡았으며 클러스터링은 event_name으로 잡았습니다.

2.1. 클러스터링을 이용한 데이터 SELECT
데이터를 SELECT 하면 어떻게 되는지 확인해 보겠습니다. 위에서 event_name을 통해서 클러스터링을 만들었습니다. 위에 스크린숏을 보시면 클러스터링 기준에 event_name이 잘 들어가 있는 것을 볼 수 있습니다. 하지만 아래의 내용을 보면 예상 실행 비용이 전체 테이블을 조회하는 것과 똑같습니다. 이상합니다. 클러스터링을 정확히 가져오지 못하는 것인가..?라는 생각이 듭니다. 혹시 모르니 그대로 실행하겠습니다.

실제로 SELECT를 실행하고 실제로 데이터의 사용을 보면 32.2GB를 처리합니다. 예상된 93.4GB보다 적은 양의 데이터를 가져옵니다. 혹시 몰라서 현재 회사에서 만들어진 실제 데이터 사용량 비용 지표를 통해서 데이터의 사용량을 확인해봤습니다.


다시 한번 확인해봤지만 역시 데이터의 사용량은 32.2GB입니다. 이로써 예상 비용과 실제 비용이 다름을 확인할 수 있습니다. 문득 갑자기 공식 홈페이지에 있는 이 말이 떠올랐습니다.
쿼리를 실행하기 전 엄격한 비용 보장이 필요하지 않습니다.
이 내용은 공식 홈페이지에 클러스터링을 사용해야 하는 경우에 대해서 이야기할 때 가장 처음에 등장하는 내용입니다. 아마도 파티션 단위로 데이터를 나눠놨기 때문에 예상 비용을 위와 같이 전체 테이블 단위로 보여주지만 실제 데이터를 읽을 때는 클러스터링 된 정렬된 데이터를 일부만 읽기 때문에 위와 같이 예상 비용과 실제 비용이 다르게 나오는 것으로 보입니다. (이 부분도 추측입니다.)
그렇다면 클러스터링과 파티션을 함께 사용하면 어떻게 될까요?
2.2. 클러스터링과 파티션을 이용한 데이터 SELECT
다음과 같이 event_timestamp를 이용하여 파티션을 사용하고 event_name을 이용해서 클러스터링을 이용해서 데이터를 SELECT를 하도록 하겠습니다. 2개를 한 번에 사용할 경우 비용적과 성능면에서 어떤 이점이 있을지 궁금하네요.

일단 예상 비용이 93GB에서 10.1GB로 확실히 많이 줄었습니다. 파티션을 이용하기 때문에 훨씬 줄어 들었고 아마도 실행 시간도 엄청나게 절감 될 것으로 보입니다. 실제로 SELECT를 실행하면 다음과 같습니다.
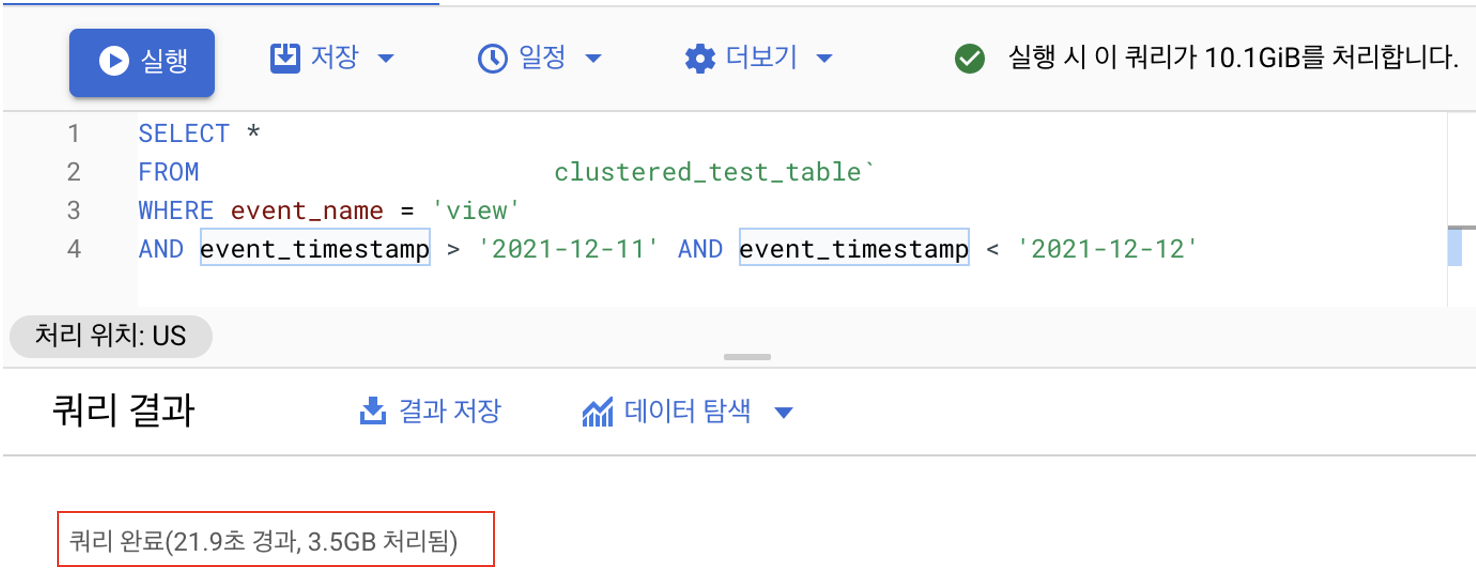
위에서 보시면 예상 비용보다 휠씬 더 작게 소요되었습니다. 파티션과 함께 사용해도 큰 이점을 볼 수 있는 것으로 보입니다. 데이터를 정렬된 내용으로 일부만 읽기 때문에 아마도 이렇게 처리 비용이 줄어든 것으로 보입니다. 하지만 여기서 한 가지 궁금한 게 있습니다. 왜 처리 시간은 눈에 보이게 줄어들지 않는가?입니다. 처리 속도의 경우는 아마도 큰 양의 데이터를 가지고 테스트를 해야 속도가 향상되는 것으로 보입니다. 100GB의 데이터로는 크게 속도를 체감 하기는 어려워 보입니다. 이러한 내용은 아래의 블로그를 통해서 확인 가능합니다.
(데이터를 너무 많이 쓰면 안 돼요...)
https://hoffa.medium.com/bigquery-optimized-cluster-your-tables-65e2f684594b
Optimizing BigQuery: Cluster your tables
BigQuery just announced the ability to cluster tables — which I’ll describe here. If you are looking for massive savings in costs and…
hoffa.medium.com
2.3. 유니크 또는 선택도가 높은 칼럼을 클러스터링으로 하면?
여기서 저는 한 가지 궁금증이 생겼습니다. 위의 event_name의 경우는 선택도가 낮은 칼럼입니다. 선택도가 낮기 때문에 집계 작업을 할 때 사용하기 좋습니다. 하지만 클러스터링을 통해서 인덱스와 같이 특정 유저를 검색하는 용도로 사용할 수 있지 않을까?라는 생각이 들었습니다. 그래서 event_name이 아닌 다른 선택도가 높은 칼럼을 이용해서 클러스터링을 만들어서 테스트를 진행해보겠습니다.
테이블에 보면 user_id라는 칼럼이 있습니다. 아마도 유저의 고유키 값으로 보입니다. 이 칼럼을 이용해서 클러스터링을 만들어서 어떻게 되는지 테스트를 진행해 봤습니다. 데이터의 경우 기존의 사용했던 데이터를 그대로 복사하여 클러스터링 칼럼만 변경하였습니다.
테이블이 설마 안 만들어지지 않을까? 싶었는데 테이블은 잘 만들어졌습니다. 테이블을 보면 기존의 event_name으로 클러스터링을 잡은 것과 user_id로 클러스터링을 잡은 것과 클러스터링 기준을 제외하고 다른 부분이 한 개도 없습니다.

이제 실제로 테스트를 진행해보려고 합니다. user_id로 검색을 했을 때 과연 얼마나 비용적으로 이점이 있을지 궁금하네요.

데이터의 예상 비용은 역시나 차이가 없습니다. 전체 테이블을 읽는 것과 같은 비용을 예상 비용으로 표기하고 있습니다. 실제로 실행해봤는데 결과가 매우 놀랍습니다... 엄청나게 차이를 보입니다. 처리 시간이 엄청나게 눈에 보이게 줄었습니다. 데이터를 처리하는 비용 또한 엄청나게 줄었습니다. 클러스터링의 효과가 이렇게 실감이 되는 게 신기합니다.

그렇다면 위의 클러스터링 2개를 동시에 걸어서 사용하면 어떻게 될까?라는 생각도 듭니다. 이렇게 하면 테이블을 집계 용도와 검색 용도로 함께 사용도 가능하고 비용, 성능적으로 두 마리의 토끼를 한 번에 잡을 수 있을 것 같다는 생각이 듭니다.

2.4. 선택도가 낮고 높은 칼럼을 동시에 클러스터링 해보기
2개의 user_id와 event_name을 클러스터링 하여 검색을 해보도록 하겠습니다. 제가 DBA라면 아마도 event_name을 선행으로 걸고 user_id를 후행으로 걸어서 클러스터링을 생성할 듯합니다. 인덱스를 만드는 것처럼 만들겠습니다. 왜 그런지 이해가 안 가면 위의 복합 인덱스 관련 글을 참고 부탁드립니다.

클러스터링을 더 잘 이용하는 것을 볼 수 있습니다. 복합적으로 걸어도 큰 문제가 없이 잘 사용하는 것을 볼 수 있습니다. 그럼 여기서 한 가지 궁금한 점이 있습니다. 클러스터의 경우 제약 조건으로 순서가 중요하다고 하였습니다. 만약 순서가 뒤에 있는 user_id만 WHERE에 넣으면 어떻게 될까요?

결론적으로 매우 느립니다. 안 탑니다... 그럼 선행으로 있는 event_name은 어떨까요? RDB에서는 위와 같이 선행으로 인덱스가 걸려 있으면 정상적으로 데이터를 Seek 해서 가져옵니다.

위의 내용을 보고 조금 놀랐습니다. 제가 알기로 클러스터링 된 모든 칼럼을 WHERE에 넣어야지 쓸 수 있다고 알고 있는데, 선행 칼럼만 넣었는데, 잘 나옵니다. 혹시나 해서 event_name만 클러스터링 된 테이블과 비교하였는데, 비슷한 용량을 씁니다. (데이터 건수 같음) 이로써 클러스터링은 RDB에서 인덱스와 거의 동일하게 사용할 수 있다고 보입니다. 아마도 집계를 할 때는 event_name을 통해서 집계를 하고 user_id로 검색을 할때는 event_name NOT IN 'a' 이런 식으로 약간의 편법으로 데이터를 조회할 수 있을 듯합니다.

물론 user_id만 클러스터링 된 테이블보다는 성능과 비용이 덜하지만 충분히 훨씬 빠르고 크게 비용이 절감되는 것을 볼 수 있습니다. 이렇게 사용하면 최적의 성능까지는 아니지만 엄청나게 크게 도움이 될 것으로 보입니다.
3. 그렇다면 클러스터링은 만능인가?
결론부터 말씀드리면 꼭 그렇진 않습니다. RDB에서는 인덱스가 있는 테이블에 INSERT를 할 때 정렬해서 들어가는 성능 때문에 INSERT 성능을 고려해서 샤딩 테이블을 사용하기도 합니다. 테이블을 날짜 단위로 쪼개서 테이블명_20220104 이런 식으로 테이블을 만들고 인덱스를 아예 만들지 않고 SELECT 시에 데이터의 범위를 물리적으로 줄임으로써 효과를 볼 수 있습니다.
그래서 이러한 테스트를 한번 진행해 봤습니다. 과연 클러스터링이 없는 테이블에 INSERT 하는 경우가 있는 경우에 시간 차이가 존재할까요? 일단 체감상으로는 (아까 테이블을 만들 때) 확실히 있었지만 수치를 보여 드리고 싶어서 테스트를 한번 더 진행했습니다. 테스트는 기존의 테이블에 10일 치의 데이터(약 100GB)를 INSERT 할 때의 시간 차이를 보여 드리고자 합니다. 테스트에는 모든 테이블에 파티션이 event_timestamp로 있습니다. 파티션은 거의 필수로 생각하기에 무조건 만든다는 조건으로 동일하게 진행합니다.
| 클러스터링 조건 | 선택도 | 소요 시간 |
| 없음 | 없음 | 1분 26초 |
| event_name | 낮음 | 1분 18초 |
| user_id | 높음 | 1분 16초 |
| event_name,user_id | 높음 | 1분 38초 |
이게 아닌데... 이상합니다. 분명히 차이가 날것이라고 생각했는데 오히려 빠른 경우도 있습니다. 물론 네트워크 등의 차이로 조금의 차이는 있겠지만 이건 ... 뭐 차이가 없다고 보는게 맞을거 같습니다. 저 같은 경우 1천만건의 ROW에 100GB를 INSERT 하는 것으로 테스트를 했는데 결과가 정말 황당 합니다. 분명히 차이가 있을 것이라고 생각 했는데 없네요...

4. 결론
위의 내용을 전부 맹신하시면 안 될 것 같은 게 저는 100GB 정도의 데이터를 가지고 테스트를 진행했다는 점을 꼭 기억해 주셔야 합니다. 데이터의 양이 보통 BigQuery를 쓰신다면 TB 단위로 쓰실 것으로 보이는데, 이 경우 어떠한 문제가 있을지 저는 알지 못하기 때문에 각자 상황에 맞게 BMT를 진행해서 사용하시는 것을 권장드립니다.
하지만 여러 가지 테스트를 거치면서 느끼지만 클러스터링은 정말로 좋은 기능으로 보입니다. 파티션과 적절하게 사용한다면 매우 큰 이점을 볼 수 있을 것으로 보입니다. 그리고 많은 분들이 비용과 실행계획을 궁금해하실 수 있는데요. 비용의 경우는 2022년 1월 4일 기준으로 공식 홈페이지에서 클러스터링을 한다고 해서 비용을 더 받거나 저장 비용을 더 받는다는 이야기는 찾기 못하였습니다.
추가적으로 실행계획의 경우 제가 테스트를 하면서 보았지만 크게 다른 실행 계획은 보이지 않았습니다. 슬롯의 사용시간이나 기타 사항에서 모든 테이블을 조회하는 것과 클러스터링을 조회하거나 파티션을 조회하거나 할 때 크게 차이가 없었습니다. 내부적으로는 다르게 동작하겠지만 그렇게까지는 세부 실행 계획을 아직 제공하지 않기 때문에 차이점을 찾지는 못했습니다.
긴 글 읽어 주셔서 감사합니다.
'GCP > BigQuery' 카테고리의 다른 글
| Unable to proceed: Could not connect with provided parameters: No suitable driver found for "jdbc:redshift" (0) | 2022.04.28 |
|---|---|
| [BigQuery] 운영 2탄 / Query 사용량 관리하기 (0) | 2022.01.14 |
| BigQuery - 운영 1탄 / 불필요한 dataset 삭제 (0) | 2021.11.10 |
| BigQuery - 테이블에서 스키마 추출 (4) | 2021.09.28 |
| BigQuery - JSON 컬럼 파싱하기 (0) | 2021.08.10 |