


안녕하세요. 주형권입니다.
지난번에 개발한 GS리테일의 데이터레이크 모니터링 시스템 도베르만에 추가적인 기능을 만들어서 만드는 과정에 대해서 공유하려고 글을 작성하였습니다. 기존에 모니터링 시스템에 관련된 글은 링크를 들어가시면 볼 수 있습니다.
https://burning-dba.tistory.com/162
[DataLake] 데이터레이크 운영 시스템 도입기
안녕하세요. 주형권입니다. 2023년 6월 30일 기준으로 어느덧 GS리테일에 입사한 지 2달을 넘었습니다. 현재 잘 적응하고 있으며 입사 이후에 정말 많은 것들을 만들고 있습니다. 이번 글은 그 첫
burning-dba.tistory.com
들어가기에 앞서 GCP 환경과 AWS 환경에서 모두 데이터 시스템을 만들고 운영 해본 입장에서 확실히 GCP가 훨씬 편하다고 느낍니다... 지극히 개인적인 생각이지만 GCP의 운영 및 확장성은 정말 엄청난 거 같습니다. (편의성도...) 지극히 개인적인 생각이지만 데이터는 GCP에서 BigQuery를 이용하는 게 운영하고 개발하는 입장에서는 너무 편한 거 같습니다. (짧은 하소연이었습니다.)
들어가며
기존에 GCP에서 BigQuery를 이용하여 누가 얼마나 Query를 사용하였는지 보여주는 지표를 만든 적이 있습니다. 당시에는 BigQuery에서 바로 볼 수 있도록 하는 기능을 제공해 주었고, 테이블 형태로 쌓을 수 있는 기능이 있어서 손쉽게 만들었는데 AWS의 Athena는 생각보다 쉽게 되지 않아서... 여러 난관을 만났습니다. 아래는 기존에 만들었던 GCP의 BigQuery에서 사용량 관리하기에 관련된 글입니다.
https://burning-dba.tistory.com/148
[BigQuery] 운영 2탄 / Query 사용량 관리하기
안녕하세요. 지난번의 BigQuery 운영 1탄 편이었던 불필요한 Dataset 삭제 이후에 2탄 BigQuery 사용량 관리에 대해서 글을 작성하였습니다. 어찌 보면 이 글이 1탄보다 훨씬 더 유용할 것으로 보입니다.
burning-dba.tistory.com
데이터 가져오기
데이터를 주기적으로 크롤링하는 방법은 위의 도베르만 도입기에 자세히 나와 있으니 참고 부탁 드립니다. 여기서 설명하는 내용은 어떠한 데이터를 어떻게 가져왔는지에 대해서 설명하고자 합니다. 우선 Athena에서는 다음과 같이 최근쿼리를 볼 수 있는 메뉴가 있습니다. (최근쿼리에 대한 설명은 링크를 참고해주세요.)
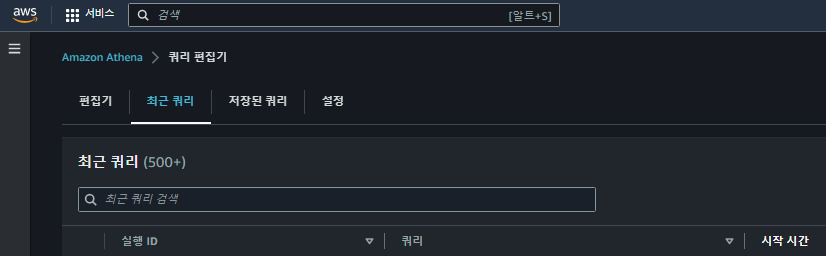
거의 실시간으로 내가 실행한 Query 및 해당 계정(Account)에서 실행한 유저의 Query 정보를 볼 수 있습니다. 최근쿼리에서는 다음의 항목을 확인할 수 있습니다. 빈칸은 자세하게 몰라서 기입하지 않았습니다.
| 컬럼 | 내용 |
| 실행 ID | Query를 실행한 프로세스의 고유 값 |
| 쿼리 | Query 내용 (전체) |
| 시작 시간 | Query 시작 시간 |
| 상태 | 현재 Query의 상태값 (성공,실패,실행중,취소 정도 보이는 듯 함) |
| 실행 시간 | Query가 실행 된 소요시간 |
| 캐시 | |
| 스캔한 데이터 | 데이터를 SCAN 한 사이즈 |
| 사용한 쿼리 엔진 버전 | |
| 암호화 |
위에 최근쿼리에 대해서 AWS 공식 가이드에서 제공하는 내용을 보면 여러 가지 기능을 제공합니다. 다운로드 및 검색도 제공을 합니다. 다만 최근쿼리의 경우 특정 개수가 넘어가면 보이지 않는 것으로 보입니다. (저희 쪽 기준으로 3~5일 정도 보이는 것 같습니다.)

그런데, 여기서 중요한 사실이 있습니다. 누가 어디서 Query를 실행했는지 알 수가 없습니다. 위의 GCP에서 BigQuery 사용량을 보여주는 이유는 누가 얼마나 어디서 Query를 실행했는지 보여주고 비용이 너무 많이 나오는 Query를 잡아서 이를 방지하기 위함이였는데, 누가 어디서 실행 했는지 알 수 없다면 반쪽짜리 기능 밖에 안된다고 생각하였습니다.
그래서 찾은 것이 CloudTrail입니다. CloudTrail은 CloudWatch와 다르게 성능보다는 누가 무엇을 어떻게 했는지에 대한 행위를 저장하는 서비스로 감사로그에 가깝습니다. 누가 무엇을 했는지 정확히 알 수 있습니다.

이 CloudTrail을 이용해서 Athena에서 누가 무엇을 실행한 지 확인하려고 하였습니다. 실제로 CloudTrail 로그를 보면 다음과 같이 Athena에서 데이터를 조회하는 기록이 나옵니다.
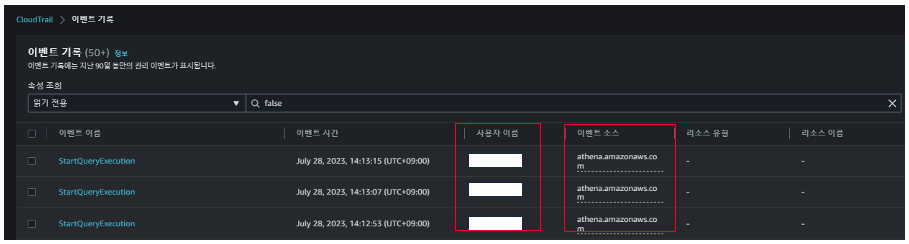
실제로 CloudTrail에 들어가면 이벤트 소스에서 athena.amazonaws.com을 볼 수 있습니다. 그리고 바로 사용자 이름 칼럼이 존재하여 누가 무엇을 하였는지 정확하게 알 수 있습니다. 클릭하여 상세 페이지를 보면 엄청나게 다양한 정보를 볼 수 있습니다. 이 CloudTrail을 boto3을 이용하여 조회하면 다음과 같은 response를 얻을 수 있습니다.
{
"eventVersion":"1.05",
"userIdentity":{
"type":"IAMUser",
"principalId":"EXAMPLE_PRINCIPAL_ID",
"arn":"arn:aws:iam::123456789012:user/johndoe",
"accountId":"123456789012",
"accessKeyId":"EXAMPLE_KEY_ID",
"userName":"johndoe"
},
"eventTime":"2017-05-04T00:23:55Z",
"eventSource":"athena.amazonaws.com",
"eventName":"StartQueryExecution",
"awsRegion":"us-east-1",
"sourceIPAddress":"77.88.999.69",
"userAgent":"aws-internal/3",
"requestParameters":{
"clientRequestToken":"16bc6e70-f972-4260-b18a-db1b623cb35c",
"resultConfiguration":{
"outputLocation":"s3://athena-johndoe-test/test/"
},
"queryString":"Select 10"
},
"responseElements":{
"queryExecutionId":"b621c254-74e0-48e3-9630-78ed857782f9"
},
"requestID":"f5039b01-305f-11e7-b146-c3fc56a7dc7a",
"eventID":"c97cf8c8-6112-467a-8777-53bb38f83fd5",
"eventType":"AwsApiCall",
"recipientAccountId":"123456789012"
}
위의 내용은 AWS 공식 가이드에서 제공하는 내용인데, 실제 내용과 크게 다르지 않습니다. 위에서 저는 필요한 여러 가지 정보를 얻을 수 있었습니다. 어느 유저가 어떠한 프로그램으로 데이터를 실행했는지 볼 수 있고 "queryExecutionId"를 이용해서 Athena에서 Query의 내용을 찾아서 볼 수 있었습니다. 결과적으로 Python으로 boto3을 이용해서 만들때 다음과 같이 만들 수 있습니다.
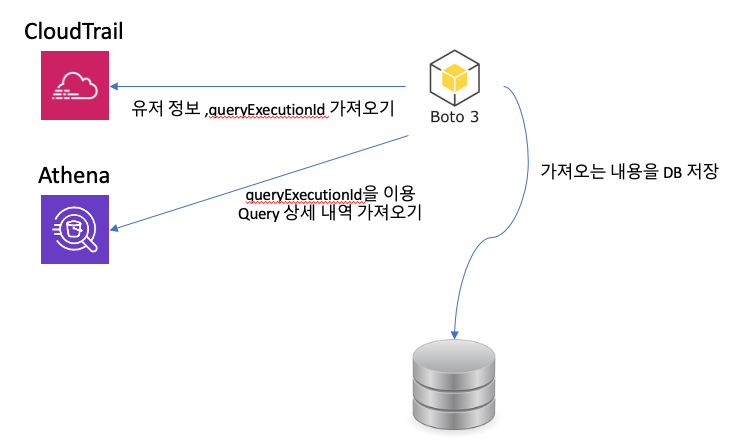
위의 그림과 같이 boto3를 이용해서 CloudTrail에서 어떠한 행위를 하였는지 찾아서 queryExecutionId를 이용해서 Athena에서 boto3를 이용하여 최근쿼리를 찾아서 데이터를 가져와서 하나의 List로 만들어서 DB에 저장하였습니다. 위에서 Athena의 최근쿼리가 3~5일 정도밖에 안 보인다고 하였는데 boto3로 가져오는 그 기간이 훨씬 깁니다. (자세히 얼마인지는 알 수 없으나, 몇 달까지 가능)
사용한 boto3는 무엇?
boto3의 경우 2개를 사용하였습니다. athena와 cloudtrail 2개입니다.
boto3.client('athena')boto3.client('cloudtrail')
boto3 cloudtrail
이 boto3의 경우 위에서 말씀드린 어떠한 행위를 하였는지에 대해서 가져옵니다. 하지만 여기서 중요한 사실이 있습니다. 아마 cloudtrail을 가져와보신 분은 아시겠지만 로그가 엄청나게 많습니다. 그래서 불필요한 로그도 가져오므로 데이터가 너무 많이 쌓이면 우리 쪽 모니터링 시스템 DB에 부하가 있을 수 있고, 불필요하게 용량을 차지해서 안 좋을 수 있습니다. 그래서 cloudtrail에 filter 같은 기능이 있어서 이 기능을 적극 활용 하였습니다.
trail.lookup_events(
LookupAttributes=[
{'AttributeKey': 'EventName','AttributeValue': 'StartQueryExecution'},
{'AttributeKey': 'EventName','AttributeValue': 'BatchGetQueryExecution'},
{'AttributeKey': 'EventName','AttributeValue': 'GetQueryRuntimeStatistics'},
{'AttributeKey': 'EventName','AttributeValue': 'GetQueryExecution'}],
StartTime=start_date,
EndTime=end_date,)
위의 내용을 보면 EventName에서 딱 4개만 가져오도록 하였는데, 위의 내용은 전부 Athena에 관련된 내용입니다. 그리고 실제로 EventSource로 athena.amazonaws.com를 찍어보면 위의 4개의 EventName 이외에도 많은 로그들이 있습니다. 이외에는 다음과 같이 EventName들이 있긴 하지만 4개 빼고는 비용이 나오지 않거나 크게 중요하지 않아 보여서 딱 4개만 가져오게 하였습니다.
이외의 Athena 관련 EventName을 참고차 함께 넣었습니다. (혹시 비용 발생하는 거 찾으시면 제보 좀...)
BatchGetNamedQuery
BatchGetQueryExecution
CreateNamedQuery
DeleteNamedQuery
GetNamedQuery
GetQueryExecution
GetQueryResults
GetQueryRuntimeStatistics
ListQueryExecutions
StartQueryExecution
StopQueryExecution
UpdateNamedQuery
이렇게 하면 3~4일 조회 시 2~30,000 건의 로그가 1,000건 정도로 줄어듭니다. 실제 대부분의 비용은 "StartQeuryExecution"에서 발생하고 나머지 BatchGetQueryExecution은 Glue로 보였습니다. (실제로 열어보면 queryExecutionId가 엄청나게 여러 개로 있습니다. 아마도 Glue의 순서에 따라서 도는 Query를 모두 표기하는 것 같습니다.)
boto3 Athena
이곳에서는 위에서 말씀드린 Query의 상세한 내용을 가져옵니다. 실행 시간이나 Query의 내용, 스캔 사이즈등을 가져왔습니다.
athena.get_query_execution(QueryExecutionId=queryexecutionid)
보면 get_query_execution을 사용하였는데, 이 API에는 조건이 QueryExecutionId 딱 1개만 가능합니다.

그래서 우선 cloudTrail을 boto3로 가져오고 While을 돌면서 get_query_execution을 수행하면서 Query의 자세한 내용을 가져오게 하였습니다. 그러면 While이 돌면서 Query의 자세한 내용 및 누가 어떻게 어디서 Query를 실행하였는지 전부를 알 수 있게 됩니다. 위의 CloudTrail을 최대한 범위를 줄여서 검색하였기에 부하도 크지 않고 금방금방 끝이 납니다.
만들다 마주친 오류...
이 내용은 제가 미리 글을 작성해두었는데요.
Your pagination token does not match your request
위와 같은 오류가 나와서 몇 시간 삽질했습니다. 혹시 하시다가 막히시면 참고해주세요.
https://burning-dba.tistory.com/166
[boto3] Your pagination token does not match your request
안녕하세요. 주형권입니다. AWS의 boto3를 이용하여 데이터 레이크 운영을 위한 개발을 하던 와중에 제목과 같은 에러를 발견하고 해결 방법에 대해서 정리 하였습니다. 우선 국내 블로그 및 외국
burning-dba.tistory.com
데이터 시각화
데이터의 시각화는 기존의 모니터링 시스템의 Superset에 함께 만들었습니다. Overview 페이지를 만들어서 한눈에 누가 얼마나 사용하는지 즉시 확인이 가능하도록 만들었습니다.

보시면 사용자와 서비스를 나누었는데요. boto3 CloudTrail로 데이터를 가져오면 sagemaker , Glue 등은 사용자명이 안 나오고 서비스명으로 나옵니다. 그래서 서비스에서 공통적으로 실행한 비용이 굉장히 크기 때문에 따로 빼서 구분이 쉽게 보여줬습니다. 이는 다음에 나오는 누적 그래프로 마찬가지입니다.
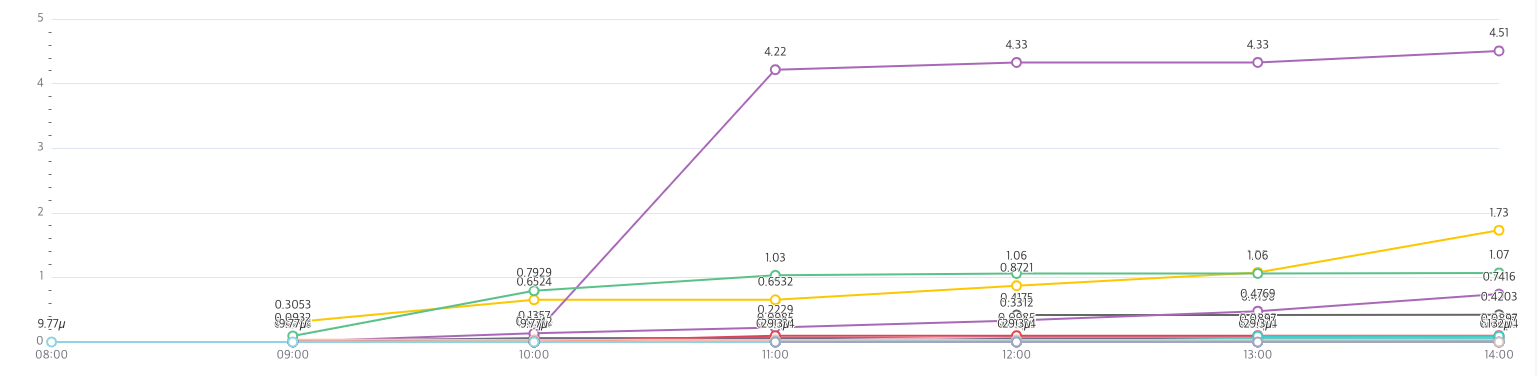
당일 누적으로 얼마나 사용했는지 보여주는 그래프를 통하여 유저로 하여금 얼마나 많이 Query를 실행하였는지 알 수 있습니다. 1시간에 한번씩 반영 하게 하여 유저들이 즉시 즉시 보고 판단이 가능 하도록 하였습니다. 추가적으로 Athena에서 제공하는 최근쿼리와 같이 어떠한 유저가 무엇을 어디서 실행 하였는지 볼 수 있는 페이지도 만들어줬습니다.
이로하여 내가 실행 한 Query가 얼마의 비용을 발생시켰는지 즉시 알고 Query를 튜닝하거나 하는 판단을 할 수 있도록 하였습니다.
알람 발송
집계를 통해서 해당 시간 동안 정해둔 사이즈 이상의 Query를 실행할 경우 알람이 오도록 하였습니다. 처음에 의도는 사용자가 정해둔 사이즈 이상의 Query를 실행하면 보내려고 하였으나... 너무 잔인하다고 판단하여 모든 Query의 실행 내역을 1시간 단위로 집계하여 보내도록 하였습니다. 엔지니어가 알람이 발생하면 자세한 로그를 보고 사용자에게 조심히(?) 알려 주도록 하고 있습니다.
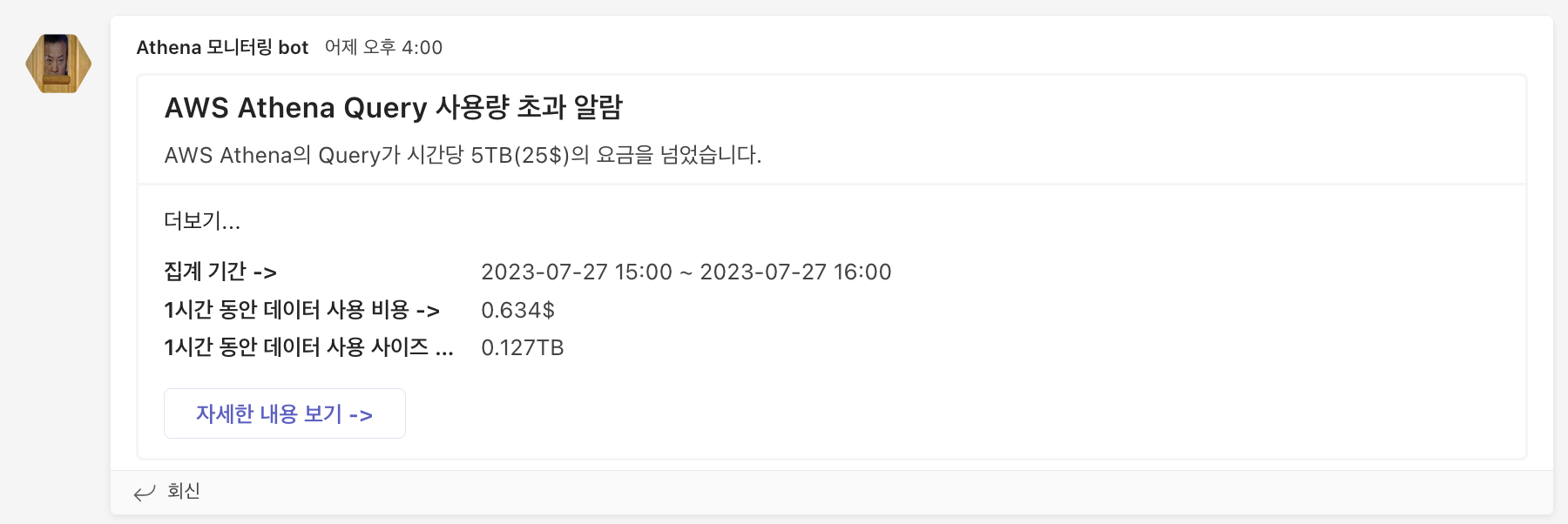
위 내용과 더불어 매일 집계를 통해서 누가 얼마나 어떻게 사용하였는지 등의 내용을 다양한 형식으로 보낼 수 있습니다. 하지만 현재로서는 시각화 지표와 이 정도 알람으로 운영에 큰 문제가 없다고 판단하여 더 이상은 만들지 않았습니다.
참고
https://sarc.io/index.php/aws/2109-boto3-cloudtrail
boto3로 CloudTrail 이벤트 가져오기
Tech Note 정보 heover1cks 님이 작성하신 글입니다. 카테고리: [ Amazon Web Services ] 게시됨: 26 August 2020 작성됨: 26 August 2020 최종 변경: 26 August 2020 조회수: 20124 개요 AWS Python SDK인 boto3를 활용해 CloudTrail의
sarc.io
'AWS > Athena' 카테고리의 다른 글
| [Athena] TOO_MANY_OPEN_PARTITIONS (0) | 2023.07.13 |
|---|