


안녕하세요. Databricks 관련해서 글을 쓰다 보니 굉장히 기본적인 모니터링 관련해서 글을 쓰지 않았네요. 제가 오늘 말씀드릴 내용은 아마도 모니터링에 가장 기본적인 Job에 대한 모니터링 방법에 관련된 내용입니다. Databricks를 운영하면서 수도 없이 많은 모니터링을 만들었지만 아마도 이 모니터링을 가장 처음 만들었던 거 같습니다.
Databricks 운영에 관련해서 다른 글을 보시고 싶으시면 아래의 글을 참고해주세요.
[Databricks] Databricks 운영 정리 - 1편 :: 데이터엔지니어 군고구마
[Databricks] Databricks 운영 정리 - 1편
안녕하세요. 계속해서 회사에서 Databricks를 하다 보니 자연스럽게 Databricks에 관련된 글을 많이 쓰고 있습니다. 이외에도 다른 공부(spark 등)도 하고 있지만 본업이 우선이기에 Databricks 쪽으로 제
burning-dba.tistory.com
들어가며
위에서도 언급하였지만 Databricks의 모니터링의 필수요소라고 할 수 있는 Job에 대해서 오늘 글을 쓰고자 합니다. Job의 경우 아래의 그림에서 나오는 메뉴에 대한 부분입니다.
해당 내용에 관련해서 제일 먼저 만든 게 알림이였습니다. 우선 알람이 오고 빠르게 실패 유무를 확인해야지 실시간으로 대응이 가능했기에 Job의 실패 여부에 대한 알람 발송부터 만들었던 거 같습니다. 이후부터는 Job의 비용에 관한 대시보드를 만들어서 보여주기 시작했고, 이를 기반으로 Job마다 얼마의 비용이 나오는지 확인하고 이 비용을 줄여나가는 작업을 하였습니다.
이번 글에서는 작업의 실패여부를 감지하여 Teams로 발송하여 알람을 보내고 작업당 비용을 수집하여 일 배 치로 지표화 하는 과정에 대해서 설명하고 있습니다. 아마도 이 정도만 해도 Databricks의 Job에 대부분의 모니터링이 될 것으로 보입니다.
1. 데이터 가져오기
우선 무엇을 하든지 데이터가 있어야 합니다. 데이터를 가져와야지 그다음에 지표화를 하거나 알람을 발송할 수 있습니다. 저 같은 경우 Databricks에서 제공하는 api를 사용하였고, 이를 AWS에 RDS에 저장하고 알람/지표를 생성하였습니다. 간략하게 아키텍처를 그리면 다음과 같습니다.
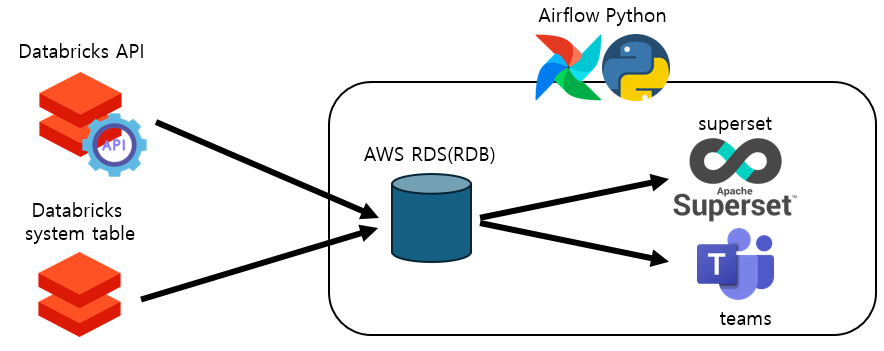
위와 같이 API와 system table에서 데이터터를 가져왔습니다. 그리고 이것을 AWS의 RDS(Aroura)에 저장하고 이를 Superset으로 시각화하고 Teams 메시지로 발송하여 알림을 만들었습니다. 이 모든 과정을 Airflow를 통해서 스케줄 처리하고 Python기반으로 코드를 만들었습니다.
1.1. Job 실패 유무 데이터 가져오기
우선 Job 실패 유무의 경우 system.lakeflow.job_run_timeline 테이블에서 정보를 가져올 수 있습니다. 그래서 아래에 이야기 할 Job의 비용 관련 테이블을 가져올때 함께 가져올수 있지만 저는 해당 테이블을 사용하지 않았습니다. 그 이유는 해당 테이블이 실시간 동기화가 아니고 랜덤 하게 동기화되기 때문입니다. 실시간으로 데이터가 동기화되지 않아서 자칫 제가 해당 정보를 수집할 때 데이터가 없거나 테이블에 업데이트가 되어 있지 않아 잘못된 알람이나 정보를 알려 줄 수 있기 때문에 저는 Databricks의 API를 사용하였습니다.
제가 사용한 API의 경우 jobs/runs/list입니다.
Databricks REST API reference
docs.databricks.com
해당 API의 경우 실시간으로 실행되는 정보를 그대로 가져오기 때문에 누락의 위험이 없고 실시간으로 작업의 실패 여부를 판단 가능 합니다. 또한 Databricks의 Rest API의 경우 현재로서는 큰 제약이 없어서 여러 번 호출해도 큰 이슈가 없습니다. (추후에 유료화 or 제한이 있을 수 있습니다.)
저의 경우 다음과 같이 변수화 하여 받았습니다. job/runs/list의 경우 굉장히 많은 항목을 자세하게 볼 수 있습니다.
job_id = job_run_row.get('job_id')
run_id = job_run_row.get('run_id')
run_name = job_run_row.get('run_name')
run_page_url = job_run_row.get('run_page_url')
creator_user_name = job_run_row.get('creator_user_name')
job_state = job_run_row.get('state').get('life_cycle_state')
job_result_state = job_run_row.get('state').get('result_state')
job_start_time = datetime.fromtimestamp(job_run_row.get('start_time')/1000)
job_end_time = datetime.fromtimestamp(job_run_row.get('end_time')/1000)
run_duration = job_run_row.get('run_duration')/1000
저는 위의 내용을 기반으로 Job의 내용을 가져와서 실패 여부를 체크하였습니다. 물론 더욱 자세하게 볼 수 있으며 여러 가지 항목을 더 필요로 할 경우 위의 링크를 통해서 필요한 정보를 가져와 주시면 좋을 듯합니다.
1.2. Job 비용 관련 데이터 가져오기
Job의 비용에 관련해서는 system.billing.usage를 참고하였습니다.
SELECT
usage_date,
workspace_id,
sku_name,
usage_metadata.job_id AS job_id,
SUM(usage_quantity) AS total_dbus_consumed
FROM system.billing.usage
WHERE usage_metadata.job_id IS NOT NULL
AND usage_date >= '{tddate}'
GROUP BY usage_date,workspace_id,sku_name,usage_metadata.job_id
위의 SQL을 보면 job_id가 IS NOT NULL을 가져옴으로써 job을 필터 할 수 있습니다. 저 같은 일 배 치로써 하루 한 번씩 RDS에 집계하면서 가져오도록 만들었습니다.
아래의 스키마 정의서에서 씐 부분을 붉은색으로 표기하였으며, 자세한 내용의 위의 테이블 링크를 참고해주세요. (이곳에 모든 칼럼이 있진 않습니다. 너무 컬럼이 많아서 잘렸습니다.)

1.3. Job 리스트 가져오기
Job의 실행 관련 데이터 이외에 가져와야 하는 게 Job의 리스트입니다. 여기에는 실행자 / 생성자가 있으므로 담당자를 알아야지 해당 담당자에게 알람을 발송할 수 있으므로 꼭 필요합니다. 또한 추가적으로 몇 가지 좋은 정보들이 있어서 저는 Job의 성공/실패를 알려주는 API와 별개로 해당 API도 호출하여 계속해서 Job 리스트를 가져옵니다.
제가 사용하는 Job리스트를 가져오는 API는 api/2.2/jobs/list이며, 아래에서 자세하게 볼 수 있습니다.
List jobs | Jobs API | REST API reference | Databricks on AWS
Databricks REST API reference
docs.databricks.com
아래와 같이 몇몇의 값을 가져와서 RDB에 저장하고 있습니다.
creator_user_email = result_job.get('creator_user_name')
run_as_user_email = result_job.get('run_as_user_name')
run_as_owner = result_job.get('run_as_owner')
job_name = result_job.get('settings').get('name')
schedule_time = json.dumps(result_job.get('settings').get('schedule'))
task = json.dumps(result_job.get('settings').get('tasks'))
create_time = datetime.fromtimestamp(result_job.get('created_time')/1000)
tags = json.dumps(result_job.get('settings').get('tags'))1.4. 가격표 가져오기
가격표 가져오기(?)라고 하여 이게 뭐지? 싶은 분들이 많으실 겁니다. Databricks의 경우 모든 가격의 표기를 USD가 아닌 DBU (Databricks Unit)으로 하기 때문에 이것을 우리가 볼 수 있도록 하려면 USD로 바꿔줘야 합니다. 그런데 가격이라는 게 환율처럼 항상 변경이 됩니다. 그래서 Databricks 내에서 제공하는 테이블을 통해서 가격표를 매일 가져와야 합니다.
가장 최신의 데이터를 가져오기 위해서 PARTITION BY를 사용하였습니다. PARTITION BY를 이용해서 가장 마지막에 업데이트된 가격에 대해서 모두 가져옵니다.
SELECT
price_start_time
,sku_name
,pricing
FROM
(
SELECT ROW_NUMBER() OVER (PARTITION BY sku_name ORDER BY price_start_time DESC) AS rank
,price_start_time,sku_name,pricing.default as pricing
FROM system.billing.list_prices
)AS T
WHERE rank = 1
가격이 업데이트될 때마다 APPEND 형태로 추가되는 것으로 보이며, 그렇기 때문에 최신 데이터만 필터 해서 가져오면 다음과 같이 가져올 수 있습니다.
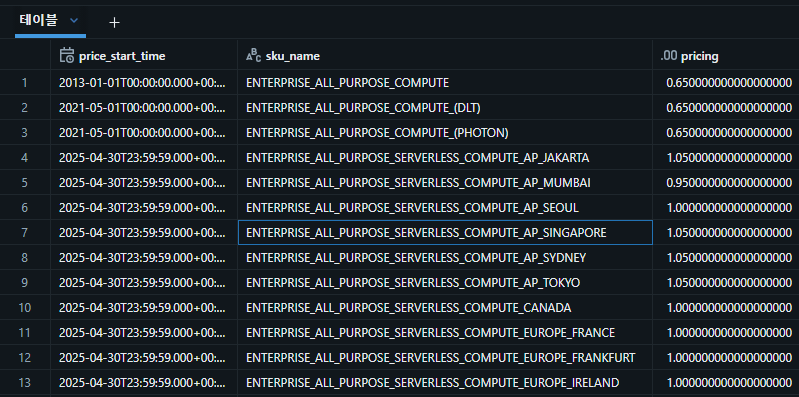
위의 내용을 가지고 sku_name과 조인하여 보여주면 DBU를 USD로 보여줄 수 있습니다.
2. 알람 보내기
알람은 Teams 기준으로 만들었습니다. 왜냐면 저희 회사에서는 공식적으로 Teams를 사용하고 있어서 Teams를 활용하였습니다. Teams를 통해서 보내는 참고할 자료는 아래의 링크를 확인해 주세요.
[Teams] Python에서 Power Automate Workflow을 이용한 Teams 메시지 전송 :: 데이터엔지니어 군고구마
[Teams] Python에서 Power Automate Workflow을 이용한 Teams 메시지 전송
안녕하세요. 주형권입니다. 최근에 Python을 통해서 특정 상황에서 Teams 채널에 메시지를 전송 할때 다음과 같이 알림이 발생하여 다른 방법으로 보내는 방법을 찾는 과정을 정리하였습니다. 이
burning-dba.tistory.com
[Python/Teams] Teams Webhook 메시지 보내기 — 데브옵스 놀이터 🎨
[Python/Teams] Teams Webhook 메시지 보내기
[Python/Teams] Teams Webhook 메시지 보내기 팀즈 채널의 커넥터에서 Incoming Webhook을 구성하면, Webhook URL을 얻을 수 있다. 파이썬의 requests와 json 라이브러리를 통해 webhook 메시지를 json형태로 전달할 수
heywantodo.tistory.com
작년부터 Teams에서 webhook을 없앤다고 하였는데 잘 서비스되고 있고 Power Automate Workflow는 아직 안정화가 안된 거 같아서 저는 webhook을 조금 더 추천드립니다. 물론 다양한 기능은 Power Automate Workflow가 조금 더 좋지만 안정성은 제 개인적 생각으로 webhook이 좋은 거 같습니다.
일단 위에서 저장한 2개의 테이블 1.1.Job 실패유무 테이블 / 1.3.Job 리스트 테이블 2개를 이용해서 아래와 같이 데이터를 만들어서 for문을 돌리면서 더 아래에 JSON을 이용해서 Teams 메시지를 발송하였습니다.
SELECT CONVERT_TZ(job_start_time, 'UTC', 'Asia/Seoul') AS job_start_time
,CONVERT_TZ(job_end_time, 'UTC', 'Asia/Seoul') AS job_end_time
,a.job_id
,a.job_name
,a.job_state
,job_result_state
,creator_user_email
,a.workspace_name
,a.run_page_url
FROM monitoring.databricks_job_task AS a -- 1.1. 테이블
LEFT JOIN monitoring.databricks_job_list AS b -- 1.3. 테이블
ON a.job_id = b.job_id
WHERE a.job_end_time >= DATE_ADD(DATE_FORMAT(NOW(),'%Y-%m-%d %H:00'), INTERVAL -1 HOUR)
AND a.job_result_state NOT IN ( 'SUCCESS','CANCELED')
AND a.job_name NOT LIKE 'TEST_%' -- TEST라고 앞부분에 넣으면 알람 안받음(테스트용은 X)
아래는 webhook 기준으로 보내는 JSON입니다. 참고해서 사용해주시면 좋을 거 같습니다. 그리고 여기에 JSON에 보시면 몇 가지 이모티콘이 있는데요. 아래에 사이트를 들어가서 키워드에 맞춰서 검색하면 알맞은 이모티콘이 나옵니다.
Storage Emojis | 📦💾🗄️🗃️ | Copy & Paste
Storage Emojis | 📦💾🗄️🗃️ | Copy & Paste
We've searched our database for all the emojis that are somehow related to Storage. Here they are! There are more than 20 of them, but the most relevant ones appear first.
emojidb.org
{
"type": "message",
"attachments": [
{
"contentType": "application/vnd.microsoft.card.adaptive",
"content": {
"type": "AdaptiveCard",
"size": "Large",
"body": [
{
"type": "TextBlock",
"size": "Large",
"weight": "Bolder",
"text": "**🚨 Databricks 작업 실패 알람**"
},
{
"type": "TextBlock",
"text": "<at>user_mention</at>",
"wrap": "true"
},
{
"type": "TextBlock",
"text": f"🌎 Workspace : {workspace_name}",
"wrap": "true"
},
{
"type": "TextBlock",
"text": f"🆔 작업 이름 : {job_name} / ({job_id})",
"wrap": "true"
},
{
"type": "TextBlock",
"text": f"📅 작업 수행 시간 : {start_date} ~ {end_date}",
"wrap": "true"
},
{
"type": "TextBlock",
"text": f"💬 작업 상태 : {job_state}[{job_state_result}]",
"wrap": "true"
},
{
"type": "ActionSet",
"actions":
[
{
"type": "Action.OpenUrl",
"title": "🌐 작업 바로가기",
"url": f'{run_page_url}'
}
]
}
],
"$schema": "http://adaptivecards.io/schemas/adaptive-card.json",
"version": "1.0",
"msteams": {
"width": "Full",
"entities": [
{
"type": "mention",
"text": "<at>user_mention</at>",
"mentioned": {
"id": f"{job_creator}",
"name": f"{job_creator}"
}
}
]
}
}
}]
}
위의 내용에 대해서 결과물은 다음과 같이 나옵니다. 아주 심플하게 만들었고 링크를 통해서 담당자가 바로 해당 Job으로 접근이 가능합니다.

3. 대시보드
대시보드의 경우 엄청 많지는 않고, 몇몇의 필요한 대시보드만 만들어서 봤습니다. Superset을 이용해서 만들었으며 요청하시면 해당 대시보드를 만든 SQL이나 여러 가지 기법은 개별적으로 메일로 보내드리겠습니다.
3.1.Job 실행 내역 대시보드

특정 Job이 갑자기 오래 걸리거나 평소에 얼마나 걸리는지 확인을 위해서 만들었습니다. 위의 내용은 모든 Job을 클릭해서 그렇지만 특정 Job을 검색하면 아래와 같이 상세하게 분석이 가능합니다. 물론 더 아래쪽에 표 형태로 존재합니다. (지울 게 너무 많아서 귀찮아서 안 붙였습니다...)

실행 내역의 경우 특정 작업이 오래 걸리거나 하는 것을 볼 수도 있고 갑자기 전체적으로 시간이 늘어난 것도 볼 수 있습니다. 이럴 경우 작업을 조정하거나 컴퓨팅 성능을 늘리거나 하는 여러 가지 조치를 취할 수 있습니다. 관련해서 작업 시간이 오래 걸리는 SQL을 추적하는 방법은 아래의 링크를 통해서 볼 수 있습니다.
[Databricks] 비효율적인 작업 추적기 만들기 :: 데이터엔지니어 군고구마
[Databricks] 비효율적인 작업 추적기 만들기
안녕하세요. 주형권입니다.정말 오랜만에 글을 쓰는 거 같습니다. 요즘 내/외부적으로 바쁘게 살고 있어서 글을 쓸 시간이 없습니다... 그래서 한 달에 1개 업로드하기도 어렵습니다.🥺 들어가
burning-dba.tistory.com
3.2. Job 실행 리스트 대시보드

어딜 가나 전체적인 현황을 보여주는 대시보드는 있어야 합니다. Databricks 자체에서 제공하긴 하지만 region을 여러 개 사용하는 사람들의 경우 하나씩 들어가서 봐야 하는 번거로움이 있습니다. 그렇기 때문에 이를 합쳐서 볼 수 있도록 1.3.Job리스트 테이블을 이용하여 다음과 같이 한 번에 볼 수 있는 대시보드를 만들었습니다.
그리고 추가적으로 실행시간을 보여줌으로써 사용자가 언제 내가 요청한 데이터가 동기화되는지 알 수 있습니다. 그렇기에 조금이나마 문의사항을 덜어줄 수 있습니다.
3.3. Job 비용 대시보드

아마도 이 대시보드가 반응이 제일 좋았던 거 같습니다. 비용에 관련해서 민감하기 때문에 대시보드를 통해서 어떠한 Job이 비용이 많이 들어가는지 한눈에 본다면 그만큼 대처가 빠르고 정확해집니다. 이 대시보드를 통해서 몇몇의 불필요하거나 비용이 많이 들어가는 Job에 대해서 튜닝을 통해서 비용을 절감하였습니다.
해당 대시보드의 경우 1.2.Job 비용 관련 테이블을 이용해서 만들어졌으며, Superset에 Pivot Table을 이용해서 만들었습니다. 아마 1.2.Job비용 관련 테이블을 잘 적재하셨다면 지표를 만드는 데는 큰 문제는 없을 것 같습니다.

관련해서 비용이 많이 나오는 경우 알람을 보내는 기능도 추가할 수 있습니다. 이건 취향(?)에 따라서 운영자가 하면 좋을 것 같습니다.
마치며
운영은 정말 끝이 없는 거 같습니다. 이렇게 길고 여러 개의 글을 썼는데 아직도 써야 하는 글이 산더미인 것을 보면 정말 끝이 없습니다. 운영은 계속해서 나오고 계속해서 진화하는 거 같습니다. 최근 AI로 인해서 많은 사람들이 직업에 위기를 느끼지만 저는 딱히 느끼지 못합니다. 왜냐면 그 AI 조차도 운영을 해야 하거든요...
그렇기 때문에 저는 오히려 운영을 고도화하고 운영에 대해서 경험이 많은 엔지니어로써 계속해서 성장하고 싶습니다. 그에 대한 몇 가지 팁 중에 오늘은 Databricks Job에 모니터링에 대해서 알아봤습니다. 어찌 보면 가장 먼저 다뤘어야 하지 않았나 싶었지만 하다 보니 Databricks Job의 모니터링을 빼먹고 있는 걸 얼마 전에 알았습니다. 그래서 부랴부랴 글을 작성하였습니다.
이글이 많은 데이터 엔지니어 나아가 데이터를 다루는 모든 분들에게 영감이 되었으면 좋습니다. 감사합니다.
'Databricks' 카테고리의 다른 글
| [Databricks] API를 이용한 Token정보 가져오기 (Python) (0) | 2025.11.18 |
|---|---|
| Databricks와 함께한 데이터 플랫폼 구축 1년 회고 (9) | 2025.07.24 |
| [Databricks] 비효율적인 작업 추적기 만들기 (6) | 2025.07.11 |
| [Databricks] Databricks 운영 정리 - 1편 (1) | 2025.05.21 |
| [Databricks] targetFileSize 테이블 옵션 (1) | 2025.04.30 |