

해당 내용은 제가 생각한 부분과 외국 블로그, 사이트에서 있는 내용을 정리 한 개념이므로 정답은 아닙니다.

들어가며
최근에 링크드인을 통해서 Data Reliability Engineer(이하 : DRE)에 대해서 관심을 갖고 이쪽으로 로드맵을 만들어 가겠다고 다짐하였습니다. 이후에 DRE에 대해서 정확히 알고자 검색을 통해서 여러 정보를 얻었습니다. 우선 이 개념은 국내에 T사 한 곳에만 있는 것 같습니다. 실제로 운영을 하고 있으며 잘 운영 중인 것 같습니다. 실제로 검색해도 T사 이외에 어떠한 한글 문서가 나오지 않고 외국 블로그나 업체에서 제공하는 정보만 있습니다.
우선 DRE라는 개념 자체가 전세계적으로 생긴 지 얼마 안 되는 직군인 것 같습니다. 그리고 국내에는 굉장히 생소한 개념으로 보입니다. 생각해 보면 Data Engineer(이하 : DE)라는 직군도 엄청 오래된 직군은 아닙니다. 제가 초창기에 DE 직군이 생겼을 때 시작해서 벌써 7년을 하고 있으니 제가 보기엔 10년이 안된 거 같습니다. 처음에 DE를 한다고 잘 다니는 대기업을 박차고 나갔을 때 다들 X 쳤다고 했습니다. 근데 저는 이 직군이 굉장히 뜰 거라고 생각했습니다. 왜냐면 데이터의 종류가 많아지고 다양해지면서 기존의 방식은 점차 살 곳을 잃을 거 같았습니다.
그 말은 사실이 되었고 전통적인 DataWarehouse Engineer(이하 : DW)들의 이직은 더욱 어려워졌습니다. (지금은 아닌거 같지만...) 그때 당시에는 이런저런 형태의 데이터를 가리지 않고 커스텀해서 하나의 데이터 플랫폼 또는 데이터 레이크에 적재하고 이를 분석할 수 있는 사람을 선호하였습니다. 그러면서 자연스럽게 전통적인 DW만 하는 사람들은 갈수록 구직이 어려워졌습니다.
그리고 오늘날 이제는 DE 조차도 이직이 어려워지고 있습니다. 본인의 특별한 색이 있는 DE들이나 출중한 실력을 가진 DE들만이 이직을 하고 있으며 그 조차도 이직의 허들은 굉장히 높아졌습니다. DE가 그만큼 직업적으로 성숙해졌고 이로 인해서 더욱 세부적인 기술을 요구하는 기업이 많아지고 있습니다. 또한 하나의 회사에서 데이터 플랫폼/레이크를 여러 개를 사용하는 경우도 많다 보니 DE조차도 개발에 중점이 아닌 운영에 중점을 두기 시작하는 곳이 많아지고 있습니다.
Data Reliability Engineering은 무엇인가?

정의
우리가 이미 많이 알고 있는 SRE(Site Reliability Engineering)에서 Site 대신 Data를 접목시킨 역할입니다. SRE이가 인프라의 신뢰성을 보장하는 역할을 하였다면 DRE는 데이터의 신뢰성을 보장하는데 중점을 둡니다. 기업에서는 데이터의 중요성이 지소적으로 커지고 데이터 파이프라인의 복잡성이 증가하면서 관리의 어려움을 겪고 있습니다. 그렇기에 DRE는 데이터가 정확하고 신뢰 할 수 있는 고품질의 데이터로써 제공되게 하고 데이터가 필요한 사람들에게 제공되며 이에 관련하여 보안에도 신경 쓰는 엔지니어링입니다.
(출처 : Data Reliability Engineering: A Guide to Ensuring Data Quality in the Modern Data Stack)
내 생각
외국 블로그/사이트에서 설명하는 내용을 보면 약간은 다르지만 모두 같은 말을 하고 있습니다. DER는 데이터의 신뢰성을 위한 엔지니어링 입니다. 데이터의 신뢰성을 보장하기 위해선 단순하게 생각하면 데이터의 품질이 있을 것입니다. 우리가 사용하는 데이터가 실제로 정상적으로 적재되었는지 정상적으로 전처리가 이루어졌는지 등의 데이터 품질이 있으며 데이터 파이프라인이 정상적으로 작동했는지도 보증해야 합니다. 왜냐하면 다음과 같은 A, B, C의 소스 데이터를 이용해서 Mart를 만들 때 실제로 A, B, C의 데이터 파이프라인이 모두 정상 작동 했는지 보증이 되어야지 Mart의 데이터가 정확한지 신뢰할 수 있기 때문입니다.

예를 들어서 login , purchase , user_info 테이블 3개를 종합하여 user mart 테이블을 만든다고 가정할 경우 3개의 소스 테이블에서 한 개의 테이블이라도 파이프라인이 동작을 안 하면 정상적인 데이터가 나올 수 없습니다. 또는 3개의 테이블 중에 한 개라도 정합성이나 데이터에 이상이 있으면 잘못된 값이 나올 수 있습니다.
이러한 단순한 파이프라인 구조에서도 데이터 파이프라인이 하나 잘못되면 문제가 생기는데, 엄청나게 복잡하고 규모가 큰 데이터 플랫폼에서는 작은 부분이 하나 틀어지면 얼마나 많은 부분의 데이터가 잘못될까요? 또한 여기에 소스 테이블을 추가하여 마트 테이블에 더욱 많은 정보를 넣기 위해서 영향도가 어떨지 등등 많은 부분을 신경 써야 할 것입니다. 그렇기에 DRE의 범위는 데이터에 관련된 대부분의 영역에서 신뢰성 있는 데이터를 제공하기 위해서 일하는 것을 의미한다고 생각합니다.
데이터에 관련된 대부분의 영역에서 데이터의 신뢰성을 위한 엔지니어링
Data Reliability Engineer은 무엇을 하는가?

정의
DRE의 역할에 대해서는 너무 다양하고 너무 설명하는 게 달라서 뭐라고 정의하기가 어려웠습니다. 하지만 결론적으로는 데이터 신뢰성을 높이기 위해서 데이터 관련된 대부분의 영역에서 활동하는 것으로 보입니다. 또한 어느 블로그에서는 DRE를 데이터 관한 소방수라고 표현하기도 하였습니다. 아래는 몇 가지 공통적으로 등장하는 역할에 대해서 몇 개 써봤습니다.
1) 모니터링 시스템 구축 데이터 신뢰성을 보증하기 위해서 데이터 파이프라인 데이터 정합성등에 대해서 모니터링 시스템을 만들어서 관리합니다.
2) 데이터 품질 관리 데이터를 사용하는 사람들에게 데이터 품질에 대해서 자동으로 검증하고 이를 기반으로 한 데이터 신뢰성 지표 제공 합니다.
3) 데이터 운영 데이터 운영이라고 하면 범위가 굉장히 큽니다. 데이터에 수명주기 데이터의 메타정보 등 여러 가지 데이터 관련 된 운영을 모두 맡는다고 할 수 있습니다. 이밖에 데이터 사용이 쉽게 하도록 교육을 하기도 합니다.
4) 데이터 사용자와 협업 데이터를 사용하는 데이터 엔지니어 / 데이터 과학자 / 데이터 분석가등과 협업하여 모두가 신뢰할 수 있는 데이터를 만듭니다.
출처 : How to become a Data Reliability Engineer
Data Reliability Engineer: 9 Skills to Help You Become One!
What is a Data Reliability Engineer – And Do You Need One?
내 생각
이 부분에서는 제 생각이 많이 반영되었습니다. 사실 어디 회사를 입사하냐에 따라서 같은 직무라도 조금씩 다른 역할을 맡습니다. 같은 DE를 하더라도 조금씩 본인의 색채가 다르듯이 DRE도 비슷한 것 같습니다. 저는 DE를 하면서 운영을 시키지 않았지만 스스로 하였습니다. DBA를 하던 시절에 버릇이 남아서 그런지 운영에 굉장히 민감하고 보수적으로 접근하다 보니 내가 편하자고 만들어서 쓰는 모니터링 시스템이 기본이 되었습니다.
제 생각에는 DRE는 DE에서 Administrator의 역할을 수행하는 직군이라고 생각됩니다. Management보다는 Administrator의 역할을 수행함으로써 운영에 제어를 더해서 관리를 하는 역할이라고 생각됩니다. 제가 회사를 처음 입사하면 항상 하는 게 모니터링 시스템 구축입니다. ( 데이터 엔지니어인 내가 새롭게 입사하는 회사에서 하는 것)
모니터링을 해야지 어느 부분에서 누수가 발생하는지 쉽게 알 수 있고 어느 부분에서 비용이 낭비되는지 알 수 있으며 빠르게 장애를 해결할 수 있습니다. 누군가에게는 별거 아닐 수 있지만 이러한 시스템 자체를 만드는 사람을 저는 회사를 다니면서 본 적이 없습니다. 물론 Datadog / Datahub와 같은 좋은 도구들이 있지만 저 같은 경우 제 입맛에 맞는 대시보드와 제 입맛에 맞는 또는 팀의 입맛에 맞는 대시보드와 알람을 만들기 위해서 그리고 내가 또는 다른 팀원이 원하는 모니터링을 만들기 위해서 직접 만드는 것을 선택하였습니다.
이러한 모니터링을 만들기 위해서는 네이밍룰이나 여러 가지 Tag에 관련해서 정책이 필요하며 카탈로그를 지표를 만들기 위해서는 카탈로그에 대한 정책도 필요합니다. 왜냐하면 나중에 알람을 만들거나 지표에 무언가를 표시할 때 Tag나 네이밍이 이상하면 한눈에 알아보기 어렵기 때문에 당연하게도 정책 수립은 필수적으로 따라옵니다.
이러한 일련의 모든 과정을 수행해야 하는 직무라고 생각이 들며 데이터에 관련된 Administrator이라고 하는 게 제가 생각하기에 가장 맞는 거 같습니다. 그래서 직무를 특정적으로 제한하기보다는 데이터 관련된 대부분의 역할을 수행하되 그 역할이 데이터의 신뢰성에 초점을 맞춰서 해야 하는 역할로 보입니다.
데이터 관련 된 대부분의 역할을 수행하되 그 역할이 데이터 신뢰성에 포커싱 된 역할
내가 생각하는 Data Reliability Engineer
사실 이 내용을 쓰기 위해서 앞부분의 내용을 여러 가지 해외 자료를 통해서 공부했습니다. Data Reliability Engineer가 무엇인지 무엇을 하는지 알아야지 어떻게 할지 고민할 수 있다고 생각이 들어서였습니다. 사실 DRE에 대해서 찾아보면 찾아볼수록 아직은 완성되지 직군인 것 같습니다. Job Description을 봐도 각기 모두 다르고 직무에 대한 이야기를 하는 것도 모두 다르기에 무언가를 한다고 딱 정해져 있기보다는 말 그대로 데이터 신뢰성을 위해서 일하는 직군으로 보였습니다.
그래서 제가 생각하기에 지금 당장 할 수 있는 DRE의 방향은 무엇일까 고민하다가 제가 기존에 해왔던 일을 접목시킨다면 이렇게 할 것 같다는 생각이 있어서 그것을 공유하려고 합니다.
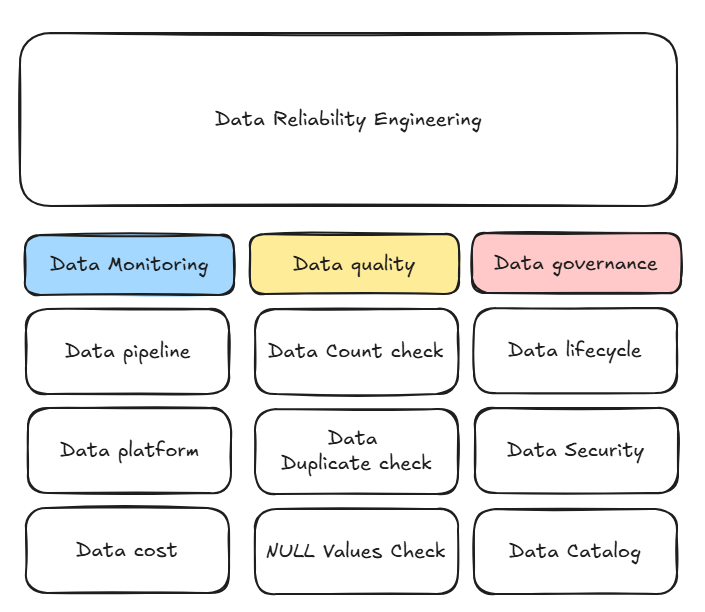
제가 생각하기에 DRE의 역할 중에 3개의 영역으로 나누고 수행하면 좋을 거 같습니다. 물론 제가 이 분야의 전문가들과는 다르게 세부적으로 더 자세하게는 이야기하기 어렵겠지만 3개의 직무 자체를 통합하여 관리하고 적용하다 보니 조금씩 해야 하지 않을까 싶습니다.
1) Data Monitoring
Data에 관련된 모니터링 시스템을 구축하는 것은 어쩌면 DRE의 가장 기본이자 핵심적인 업무가 될 것이라고 생각합니다. 앞서 이야기하였듯이 데이터 파이프라인의 동작이 끊기는 경우 마트 데이터 또는 팩트 데이터의 잘못된 값이 입력될 수 있기에 이를 즉시 알리는 모니터링 시스템을 만드는 부분에 대해서 생각할 수 있을 거 같습니다.
데이터 파이프라인의 경우 각종 시스템에서 각기 다른 소스로부터 오기 때문에 파이프라인의 모니터링을 한눈에 볼 수 있도록 만드는 것이 핵심 일 것 같습니다. 또한 누구나 알기 쉽고 빠르게 대처가 가능하도록 하는 것이 중요할 거 같습니다.
추가적으로 파이프라인의 성공 실패뿐 아니라 이를 실행시키는 플랫폼의 리소스나 사용량에 대해서도 모니터링이 필요할 것 같습니다. 예를 들면 S3의 사용량이나 Spark의 모니터링등을 하나의 지표에서 함께 볼 수 있다면 굉장히 도움이 될 것 같습니다.

여기에 더불어 각종 리소스에 관련된 비용을 볼수 있도록 한다면 비용적으로도 도움이 많이 될 것으로 보입니다. 이는 과도하게 사용되는 리소스를 찾아서 비용을 최적화할 수 있으며 성능과도 연관되게 볼 수 있습니다. 다양한 데이터 플랫폼이 과금 구조가 사용한 만큼 비용을 지불하기에 비용이 많이 소모되는 작업을 찾아서 성능을 튜닝하여 비용을 낮추고 성능을 좋게 만드는 효과도 불러올 수 있다고 생각됩니다.
2) Data Quality
데이터의 품질 또한 DRE의 주요 업무라고 생각됩니다. 소스로부터 타깃까지 데이터가 정상적으로 적재되었는지 가장 기본이 되는 ODS부터 시작해서 마트와 팩트 테이블에 이르기까지의 여러 가지 정합성 모니터링을 통해서 데이터의 품질을 올릴 수 있을 것 같습니다.

아주 간단하게는 건수 체크를 통해서 소스로부터 타깃으로 데이터가 그대로 적재되었는지를 볼 수 있을 것이며, 필요에 따라서 Primary Key를 통해서 중복 체크를 해서 데이터의 중복이 있는지 볼 수도 있습니다. Primary Key가 없는 로그성 데이터 또는 RDBMS로부터 오는 데이터가 아닌 경우 일자별로 로그의 건수의 추이를 보고 가중치를 부과해서 가중치 이상 또는 이하로 데이터가 들어오거나 또는 너무 많이 들어올 경우 알람을 보낼 수도 있습니다.
또한 NULL의 비율이나 NULL 값이 있는지 체크를 통해서 NULL로 들어오면 안 되거나 너무 많이 들어오면 이상이 있는 경우를 모니터링할 수도 있습니다. 실제로 ETL 하는 과정에서 변환하는 과정에서 데이터의 타입 변경이 자동으로 이루어지거나 인식하지 못하는 경우에 NULL로 잘못 들어오는 경우가 실제로 많이 발생합니다. 또는 실수로 인한 잘못된 패치로 인해서 아예 NULL로 들어오는 경우도 실제로 많이 있습니다.
3) Data Governance
제가 자세히 알지 못하는 영역이지만 작게나마 수행하고 있던 영역입니다. 실제로 Data Governance 영역의 경우 견고하게 설계된 회사가 많지 않고 실제로 이 부분은 엄청나게 많은 지식을 요구하기에 몇몇 필요한 부분만 적용했었습니다. (저는 그랬습니다.)
수많은 Data Governance 영역에서 저의 경우 데이터 수명주기에 대한 정책을 세우고 관리하였습니다. 왜냐하면 이 부분은 데이터의 저장소 비용과 처리 비용과 직접적으로 연관되기에 신경을 많이 쓸 수밖에 없는 부분입니다. 가장 많이 신경 썼던 부분은 S3 저장소로써 중간 저장소 역할을 하기도 하고 최종 저장소 역할을 하기도 합니다. 예를 들어 RDBMS에서 데이터를 S3에 저장하고 이를 여러 곳에서 사용한다고 하면 S3의 비용이 아무리 싸더라도 중간 산출물인 경우 또는 집계를 위해서 데이터를 S3에 저장하고 있다면 S3 수명주기를 통해서 데이터를 관리할 필요가 있습니다.
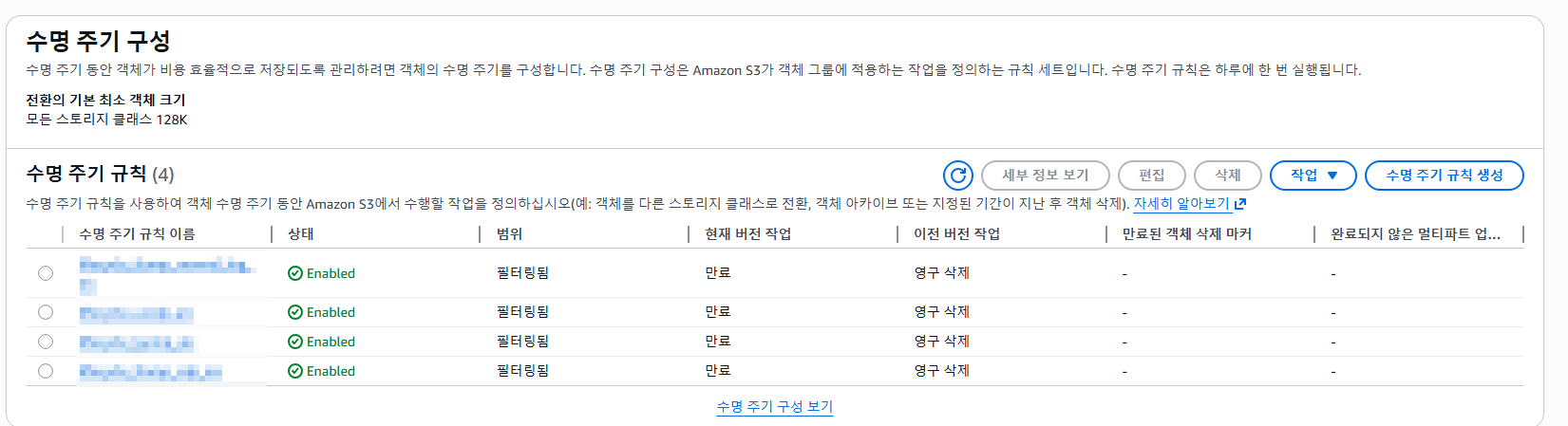
실제로 AWS S3에서는 이와 같은 기능을 제공하고 있지만 각 S3 Bucket마다 일일이 들어가서 봐야 하는 번거로움이 있습니다. 그래서 DRE의 경우 이러한 정보를 한눈에 볼 수 있는 지표나 알림을 보여주는 역할을 해야 한다고 생각합니다.
또한 보안과 관련된 일에도 여러 가지 모니터링을 통해서 알림을 받거나 관리 하는 지표를 만들수 있습니다.
이를 통해서 주기적으로 Access Key 또는 여러가지 Key 파일을 관리하고 주기적인 교체를 할 수도 있습니다. 또는 담당자에게 만료 기간이 도래 하였음을 알림으로써 각 담당자가 직접 변경을 할수 있도록 도울 수도 있습니다.
이밖에도 데이터 카탈로그 정보를 관리함으로써 데이터 스키마 변경 내역을 기록하고 이를 문서화할 수 있으며 언제든지 변경 부분에 대해서 누구나 쉽게 보도록 만들 수 있으며 현재 최신 상태의 카탈로그도 제공해야 한다고 생각합니다. 여기에 더불어 데이터에 관련된 여러 가지 Meta 정보를 수집하여 제공도 가능합니다. 예를 들면 현재 테이블의 건수와 테이블의 마지막 업데이트 시간등을 표기하여 데이터를 사용하는 사람으로 하여금 해당 데이터의 신뢰성을 더욱 높일 수 있습니다.
마치며

사실 DRE는 저에게 엄청나게 도전적이고 모험적인 직무인 거 같습니다. 아직 국내에서는 굉장히 생소한 개념이며, 해외에서도 찾아보면 각기 다르게 이야기하고 있습니다. 무엇이 맞다 틀 리다를 이야기하기보다는 어느 방향성으로 데이터의 신뢰성을 올리느냐가 중요해 보입니다. 데이터의 신뢰성을 올린다고 하는 의미가 저에겐 너무 추상적으로 다가오긴 합니다. 어떻게 하면 신뢰성을 올릴 수 있는지는 사람마다 또는 기업마다 모두 다르다고 생각하기 때문입니다.
결론적으로 DRE를 말하자면... 솔직히 말해서 데이터 운영에 관련된 모든 일 하는 사람으로 보입니다. 이게 진짜 범위 자체의 경계가 없고 모든 데이터 관련 운영 업무에 투입이 될 수 있으며 데이터베이스, 데이터웨어하우스, 데이터레이크 등 데이터가 들어가면 모두 왠지 운영적으로 봐야 할거 같습니다.
그래서 당장에는 우선 데이터 운영의 부담을 덜어주면서 데이터 품질을 올리는 부분에 집중하는 게 맞다고 생각됩니다. 이 부분도 굉장히 추상적이지만 생각해 보면 제가 데이터엔지니어를 하면서 팀에서 필요하다고 생각하거나 내가 보고 싶어서 만드는 여러 가지 업무들이 데이터 운영의 부담을 덜어주고 데이터 분석가나 데이터 과학자 나아가 데이터를 사용하는 데이터와 관련이 없는 직군이지만 데이터를 사용하는 모든 사용자들에게 데이터 신뢰도를 올렸습니다.
예를 들면 데이터 파이프라인의 종료되는 시간을 계산해서 테이블의 최신 업데이트 주기를 보는 지표를 만들어서 사용자들이 언제쯤 데이터를 보면 될지 알 수 있도록 하였으며, 데이터가 중복되지 않도록 추세 또는 PK를 통해서 이 데이터가 실제로 잘 쌓이고 있다는 지표등을 제공하여 데이터를 사용하는 사람들이 안심하고 쓰도록 하였습니다.
아마도 제가 DRE 직무를 맡게 된다면 시키는 일 + 내가 했던 일 2개를 병행 할거 같습니다. 위에서 제가 해왔던 일이면서 필요해 보이는 일을 정리하였지만 이밖에도 DRE의 잠재성(?)은 무궁무진하다고 생각됩니다. 하여 회사에서 추구하는 DRE로써의 역할은 언제나 열어놔야 한다고 생각합니다.