AWS
[AWS] awswrangler
DE 군고구마
2023. 8. 7. 16:06
반응형

안녕하세요. 주형권입니다.
최근에 계속해서 AWS환경에서 Iceberg를 이용한 데이터 ELT를 하고 있다 보니 AWS 관련하여 많은 것을 하고 있습니다. ELT 파이프라인을 모두 손수 만들다 보니 AWS Iceberg의 테이블에 데이터를 직접적으로 넣기 어려웠고 이런저런 내용을 찾다 보니 awswrangler라는 SDK를 발견하여 소개 하고자 합니다.
awswrangler SDK는 복잡하지 않고 단순히 아래의 과정으로 데이터를 Iceberg에 넣습니다.
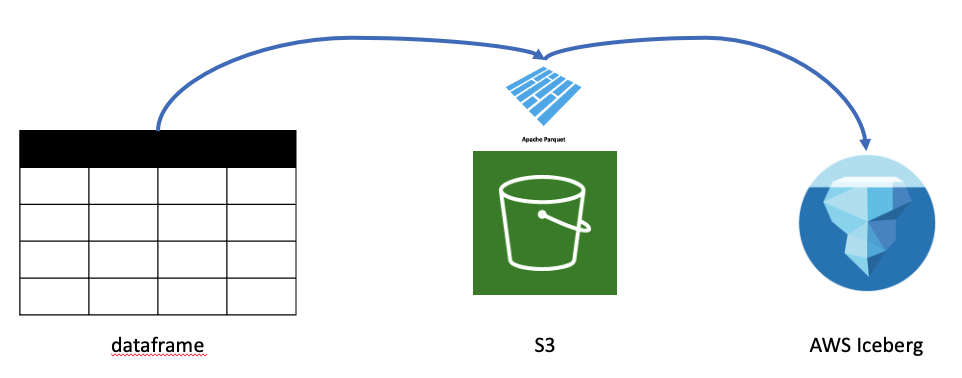
데이터를 Python에 dataframe 형태로 만들었다가 S3에 parquet로 내리고 그 데이터를 Iceberg에 Import 합니다.
또한 awsrangler는 다음의 파라미터를 받아서 사용합니다.

위에는 굉장히 많은 파라미터가 있는데 저는 저기서 일부만 사용하였습니다. 제가 사용한 파라미터는 아래에 있는 내용인데요. 왜 이것을 사용하였는지 소개해볼까 합니다. 제가 awsrangler를 사용한 이유는 Iceberg 테이블을 임시로 생성하고 Iceberg 원본 테이블과 Merge를 하여 데이터를 Upsert 하려고 하였습니다.
awswrangler.athena.to_iceberg(
df =
,database=
,table=
,table_location=
,temp_path=
,boto3_session=
,data_source=
,dtype=
)
| 파라미터명 | 파라미터 정의 |
| df | python의 pandas dataframe 입니다. |
| database | Iceberg 테이블을 생성 할 데이터베이스명 |
| table | Iceberg 테이블을 생성 할 테이블명 |
| table_location | 테이블 위치 (S3의 위치 입니다.) Iceberg를 만들면 parquet 파일이 생기는데, 이 파일이 위치 할 S3의 Path입니다. |
| temp_path | 위에서 dataframe을 S3에 parquet로 내린다고 하였는데, 이 내리는 위치입니다. * 이 데이터를 작업이 끝난 후 지워지지 않습니다. |
| boto3_session | boto3의 세션입니다. 세션을 굳이 넣어주는 이유는 awsrangler에는 Access key / Secret key를 받는 파라미터가 따로 없어서 환경변수에 등록되지 않고 key를 불러와서 쓸 경우 session을 잡아주고 파라미터로 넘겨야 합니다. |
| data_source | 데이터를 쓰는 카테고리명 |
| dtype | * 이 파라미터가 굉장히 중요합니다. Iceberg 테이블의 데이터 타입을 지정하여 입력 합니다. 이렇게 하지 않을 경우 dataframe에서 받은 값을 기준으로 판단해서 넣기 때문에 자칫 데이터가 깨져서 안들어가는 경우가 있습니다. |
아래는 오라클 데이터베이스의 결과를 Iceberg 테이블에 넣는 Python 코드 입니다.
import cx_Oracle
from pandas import DataFrame
import awswrangler
import boto3
#rdb connect infor
ora_con = cx_Oracle.connect('YOUR ORACLE CONNECT', encoding="UTF-8")
ora_cursor = ora_con.cursor()
#boto3 session
session = boto3.Session(aws_access_key_id='YOUR ACCESS KEY' ,aws_secret_access_key='YOUR SECRET KEY',region_name='YOUR REGION')
query = f"""
QUERY
"""
ora_cursor.execute(query)
select_result = ora_cursor.fetchall()
df = DataFrame(select_result)
df.columns = [x[0] for x in ora_cursor.description]
awswrangler.athena.to_iceberg(
df = df
,database='DATABASE NAME'
,table='TABLE NAME'
,table_location='ICEBERG TABLE Parquet file location'
,temp_path='ICEBERG TEMP Parquet file location'
,boto3_session=session
,data_source='awsdatacatalog'
,dtype={'DATA TYPE'}
)반응형